

Dia desses chegou um tíquete na minha fila. Era um usuário pedindo auxílio para avaliar um problema de performance na sua base de dados. Ele estava excluindo um único registro de uma tabela grande (200 milhões de linhas) e a operação estava demorando vários minutos. Situação estranha, então fui investigar.
Problema
Vi que a declaração de SELECT sobre o mesmo registro rodava em menos de dois segundos (custo total de operação de 0,0032831). Mas consegui reproduzir o problema apontado pelo usuário: o DELETE neste registro demorava mais de seis minutos (custo total de operação de 2082,29)!
Talvez eu ainda estivesse sonolento, mas confesso que não tinha entendido a origem do problema até olhar o plano de execução das consultas J. A Figura 1 mostra o plano de execução da operação de SELECT. Como era de se esperar, ele é extremamente simples, fazendo um CLUSTERED INDEX SEEK e depois o SELECT dos campos desejados.
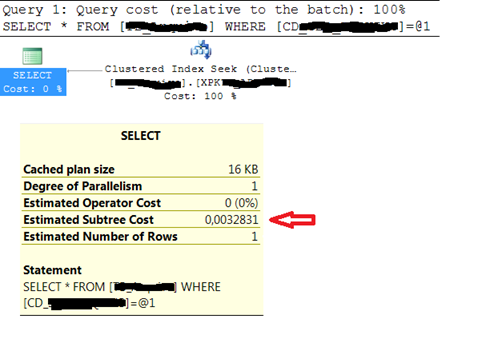
Mas o plano de execução do DELETE era muito diferente. Tinha uma “árvore” de ações afetando vários objetos. E foi isso que me mostrou a causa raiz do problema. (Veja Figura 2).
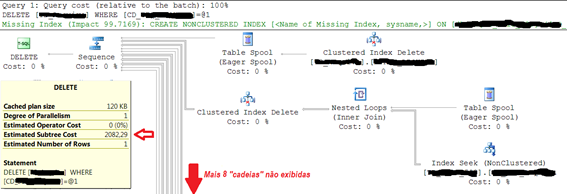
Observe na Figura 2 que as duas cadeias de operações que estão visíveis incluem a operação CLUSTERED INDEX DELETE e, portanto, é evidente que este DELETE está afetando outras tabelas além da tabela mencionada na declaração de DELETE. E sempre pesquisando o mesmo código usado no DELETE original.
Aí ficou fácil! O problema estava sendo causado por uma ação de DELETE CASCADE, estabelecida na definição de chaves estrangeiras (FKs). Todas as tabelas que usavam este código, tendo uma chave estrangeira ou sendo a tabela de referência da chave estrangeira, estavam sendo afetadas pela ação de DELETE.
Solução
Estabelecido o problema, restava definir o que fazer para saná-lo. Era preciso responder três perguntas para melhorar a performance da declaração de DELETE:
- Qual era a tabela referenciada na definição da chave estrangeira da tabela original e quais outras tabelas possuíam FKs iguais à desta tabela original?
- As tabelas envolvidas neste processo possuíam um índice clusterizado?
- Os campos onde foram criadas as FKs possuíam também um índice (neste caso, índice não-clusterizado)?
Obs: Alguns DBAs vão discordar da necessidade de haver um índice clusterizado nas tabelas que têm FKs. Pessoalmente, eu crio índices clusterizados em qualquer tabela que tenha mais que mil registros. E, além do mais, a existência de um índice clusterizado costuma melhorar a performance de todos os demais índices criados na tabela (pelo fato do novo índice criar um catálogo sobre dados teoricamente mais organizados).
Para identificar estas tabelas, eu preferi fazer uma consulta usando tabelas de catálogo do SQL Server (veja Listagem 1).
Listagem 1: pesquisando chaves estrangeiras (FKs) com CASCADE
-- ===============================================================
-- pesquisando tabelas que se relacionam
-- ===============================================================
SELECT
cast(SO.NAME as varchar(20)) + '.' + cast(O.NAME as varchar(100)) AS TAB_FK,
cast(C.NAME as varchar(100)) AS COLUNA_FK,
cast(FK.NAME as varchar(100)) AS NOME_FK ,
cast(SR.NAME as varchar(20)) + '.' + cast(R.NAME as varchar(100)) AS TAB_REFERENC,
cast(CR.NAME as varchar(100)) AS COLUNA_REFERENCIADA,
FKRULE.DELETE_RULE AS REGRA_DELETE,
FKRULE.UPDATE_RULE AS REGRA_UPDATE
FROM SYS.FOREIGN_KEYS FK
INNER JOIN SYS.ALL_OBJECTS O ON O.OBJECT_ID = FK.PARENT_OBJECT_ID
INNER JOIN SYS.SCHEMAS SO ON O.SCHEMA_ID = SO.SCHEMA_ID
INNER JOIN SYS.ALL_OBJECTS R ON R.OBJECT_ID = FK.REFERENCED_OBJECT_ID
INNER JOIN SYS.SCHEMAS SR ON R.SCHEMA_ID = SR.SCHEMA_ID
INNER JOIN SYS.FOREIGN_KEY_COLUMNS FKC
ON FKC.constraint_object_id = FK.OBJECT_ID
INNER JOIN SYS.ALL_COLUMNS CR
ON FKC.PARENT_OBJECT_ID = CR.OBJECT_ID AND FKC.parent_column_id = CR.COLUMN_ID
INNER JOIN SYS.ALL_COLUMNS C
ON FKC.PARENT_OBJECT_ID = C.OBJECT_ID AND FKC.constraint_column_id = C.COLUMN_ID
INNER JOIN INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS FKRULE
ON FKRULE.CONSTRAINT_NAME = FK.NAME
WHERE R.NAME = 'xxxxx'
ORDER BY 1,2,3
Em seguida, confirmei que todas as tabelas da minha listagem possuíam um índice clusterizado. Mas a maioria das tabelas não possuía índice sobre o campo onde se definia a FK. Isso era muito impactante, porque as pesquisas realizadas durante o “CASCADE” seriam feitas sobre este campo.
Como não existia um índice no campo pesquisado, o otimizador de consultas era obrigado a fazer em cada uma das tabelas uma operação “CLUSTERED INDEX SCAN” para localizar o registro desejado. E a performance ficava muito abaixo daquela que se obteria caso houvesse índice no campo de pesquisa (porque aí o otimizador faria uma operação “NON-CLUSTERED INDEX SEEK”).
Aliás, eu já escrevi isso em outros artigos: é sempre uma boa ideia indexar os campos que têm FKs. Note que FKs, por definição, estabelecem um relacionamento formal entre duas tabelas. Sendo assim, sempre que duas tabelas formalmente relacionadas forem usadas numa consulta, a junção destas tabelas será feita através da chave primária da tabela de referência e da FK da tabela dependente.
Na Listagem 2 eu mostro o script de criação dos índices que faltavam nas tabelas que faziam parte do “CASCADE”.
Listagem 2: script de criação de índices nos campos com FKs
-- =============================================================== -- criação de índices -- =============================================================== CREATE NONCLUSTERED INDEX [IX_t1campoX] ON [Tabela1] (campoX) ON [FileGroupIndex] ; CREATE NONCLUSTERED INDEX [IX_t2campoX] ON [Tabela2] (campoX) ON [FileGroupIndex] ; CREATE NONCLUSTERED INDEX [IX_t3campoX] ON [Tabela3] (campoX) ON [FileGroupIndex] ; CREATE NONCLUSTERED INDEX [IX_t4campoX] ON [Tabela4] (campoX) ON [FileGroupIndex] ; CREATE NONCLUSTERED INDEX [IX_t5campoX] ON [Tabela5] (campoX) ON [FileGroupIndex] ;
Resultado
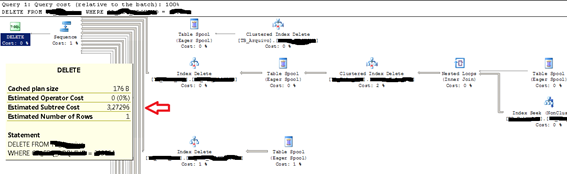
Uma vez implementados os novos índices, repeti o teste para verificar o que aconteceria com o DELETE CASCADE. E o resultado foi impressionante.
O custo total de execução da declaração baixou de 2082,29 para 3,27296. Isso quer dizer que o custo caiu 99,84%! E o tempo de execução caiu de cerca de cinco minutos para algo em torno de dez segundos. A Figura 3 mostra o plano de execução desta consulta.
Conclusão
Vimos aqui mais um exemplo sobre como ações simples podem ter um efeito radical na operação do seu banco de dados.
Criação de índices sobre campos que contenham chaves estrangeiras é uma boa prática, como eu comentei anteriormente. Mas quando se trata de relacionamentos definidos com CASCADE, seja DELETE ou UPDATE, a criação de índices nestes campos é realmente essencial.
Referências
- ROBIDOUX, Greg. Identify all of your foreign keys in a SQL Server database. MSSQL TIPS. 05/Janeiro/2007: http://www.mssqltips.com/sqlservertip/1151/identify-all-of-your-foreign-keys-in-a-sql-server-database/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?