

Neste artigo de duas partes, estamos vendo como ler e interpretar logs do SQL Server. A primeira parte do artigo está neste link.
***
O que acontece após o truncamento
backup log demolog to disk = 'c:\temp\demolog.trn'
Após realizar um backup do log de banco de dados para uma pequena demonstração, isso desencadeou o truncamento do log: uma vez que os registros de log são copiados, não há necessidade de mantê-los no log do banco de dados ativo, de modo que o espaço no arquivo LDF pode ser reutilizado para novos registros de log. Veja o documento Como reduzir o log do SQL Server para obter mais detalhes sobre como isso funciona. Mas se eu tentar agora localizar os dados que procurei anteriormente, nenhuma das minhas consultas utilizadas anteriormente conseguirá localizar qualquer coisa no log. Para localizar agora os registros que estava buscando anteriormente, agora tenho que buscar especificamente nos arquivos de backups do log:
select [Current LSN], [Operation], [AllocUnitName], [Transaction Name]
from fn_dump_dblog (
NULL, NULL, 'DISK', 1, 'c:\temp\demolog.trn',
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT)
where [Transaction ID] = '0000:000002e1';
Para uma breve introdução em fn_dump_dblog, veja Usando fn_dblog, fn_dump_dblog, e restaurando com STOPBEFOREMARK a um LSN. Ter a capacidade de analisar backups do log de banco de dados é fundamental em tais investigações forenses. As mesmas técnicas aplicáveis a quem eu mostrava usando fn_dblog, mas normalmente você vai ter que procurar através de muitos arquivos de backup do log.
Quando Lock Information não ajuda
Como vimos, a coluna [Lock Information] é de grande ajuda para localizar o registro de log de interesse, mas há casos em que essa informação está ausente do log. Isso ocorre quando o registro nunca foi bloqueado de forma individual, por exemplo. Quando o escalonamento de bloqueio ocorreu ou uma estratégia de bloqueio de tabela foi usada e um bloqueio de maior granularidade foi adquirido, utilizamos:
delete top(1) from demotable with (tablockx) select [Current LSN], [Operation], [Transaction ID], [AllocUnitName], [Page ID], [Slot ID], [Lock Information] from fn_dblog(null, null);

Quando a TABLOCKX que foi utilizada [Lock Information] não contém o recurso de hash de bloqueio para a linha específica que foi excluída, ela contém o registro do bloqueio de tabela X. No entanto, o registro de resultados úteis de log ainda contém a imagem da linha excluída e ainda podemos pesquisar usando o [Log Record] ou os campos (de 0 a 5) do conteúdo do registro. O [Page ID] e o [Slot ID] também estão presentes e poderíamos usá-los para tentar identificar os registros que afetaram a linha na qual estamos interessados.
Outro caso em que fica difícil investigar o log é relacionado a operações minimamente registradas. Informações registradas minimamente significam que o log contém apenas um breve registro que descreve o fato de que uma determinada página contém alterações minimamente registrados, e o motor SQL Server deve garantir que essa página é descarregada para o disco antes de confirmar a transação – consulte operações que podem ser minimamente registradas. Nesse caso, o único registro que você terá será o LOP_FORMAT_PAGE com o [Page ID] da página que contém as operações minimamente registradas. A boa notícia, para tais investigações, é que apenas o comando INSERT e as atualizações de escrita podem ser minimamente registradas (outros exemplos são WRITETEXT/UPDATETEXT), de modo que o problema de espaço devido ao tamanho do log é reduzido como a maioria das modificações de dados, especialmente as modificações acidentais, que não podem ser minimamente registradas e vão deixar um rastro completo no log. Há também um caso oposto, quando o log contém mais informações sobre atualizações: quando a tabela é um artigo em uma publicação de replicação transacional, mas não vou entrar em detalhes sobre este assunto.
Considerações práticas
Minha breve demonstração opera em um pequeno log. Em casos reais, não é raro ter que cavar um registro de log de milhões de pessoas. E isso é especialmente muito, muito lento. Na minha experiência, é geralmente melhor copiar o log primeiro para uma tabela temporária – ou, pelo menos, as áreas de interesse e uma parte relevante do conteúdo. Essa tabela pode ser, então, indexada conforme necessário (por exemplo, pelo [Transaction ID]), e a análise pode ser feita muito mais rápido. Também ajuda se for possível restringir o início e o fim do LSN de interesse, porque o fn_dblog pode retornar resultados muito mais rápido se restringido a LSNs conhecidos. Quanto menor o intervalo (LSNs mais adequados), mais rápida será a investigação. Tenha cuidado, porém, pois como o fn_dblog fará um dump de memória do servidor se os que LSNs passarem forem incorretos… em um servidor de produção ao vivo, isso pode se equiparar a vários minutos de um congelamento completo do SQL Server!
Mudanças DDL
A análise de log pode ser usada para investigar modificações para o esquema de banco de dados (DDL) em busca de mudanças importantes usando os mesmos métodos como os utilizados para analisar as alterações dos dados. Basta lembrar que os bancos de dados armazenam seu esquema dentro deles mesmos e que cada objeto é descrito em um ou mais catálogos de tabelas. Todas as alterações DDL acabam como alterações de dados feitas para essas tabelas de catálogo. Entretanto, interpretar as alterações de catálogo (insert/update/delete de linhas em tabelas de catálogo) não é algo trivial. O fato de que todas as alterações DDL são mudanças no catálogo também significa que todas as alterações DDL possuem a mesma aparência. Um LOP_INSER_ROWS em sys.syschhobjs poderia significar um CREATE TABLE, mas poderia também significar um CREATE VIEW ou CREATE PROCEDURE. Além disso, o comando CREATE TABLE foo será muito similar a um comando CREATE TABLE bar ao analisar o log. Uma das principais diferenças em relação a alterações de dados de log é o uso de bloqueios de dados para identificar linhas: com DDL, não se deve tentar seguir os locks de dados reais (locks nas linhas do catálogo da tabela adquiridos como as alterações DDL estão sendo aplicadas como INSERT básico / UPDATE / operação de exclusão com DELETE. Em vez disso, você deve tentar localizar bloqueios de metadados. Nas operações gerais, o DDL vai começar com um registro de bloqueio SCH_M que contém o ID de objeto que está sendo modificado.
Outro problema com a realização de análise de modificação de esquemas de dados usando o log é que a forma como o SQL Server usa o catálogo do sistema para armazenar suas alterações de metadados muda entre releases. Assim, mesmo que você tenha descoberto uma maneira de interpretar o log para compreender que tipo de mudança ocorreu na DDL, será possível descobrir que uma outra versão do SQL Server usa uma estrutura de catálogo do sistema muito diferente, e localizar mudanças pode ser completamente diferente nessa versão. Você pode contar com o catálogo do sistema (e, portanto, as operações DDL são exibidas da forma como aparecem no log) como sendo consistente entre as edições do SQL Server e entre os service packs e atualizações cumulativas da mesma versão (vou abordar esse aspecto mais adiante, embora exista um par de exceções, do qual não vale a pena falar agora).
Usando Object ID
A melhor maneira de localizar operações DDL que afetaram um objeto é localizar as transações que exigiam um bloqueio SCH_M nesse objeto. Use OBJECT_ID para obter o valor do Object ID, e em seguida, encontre o padrão N’%SCH%<object id>%’ na coluna Lock Information. Por exemplo, digamos que estou procurando mudanças para Object id de número 245575913:
select [Current LSN], Operation, [Lock Information], [Transaction ID], [Description] from fn_dblog(null, null) where [Lock Information] like N'%SCH%245575913%'
 Assim, duas operações podem ter adquirido um bloqueio SCH_M neste objeto: 0000:000002e6 e 0000:000002ea. Então, vamos analisar estas duas operações:
Assim, duas operações podem ter adquirido um bloqueio SCH_M neste objeto: 0000:000002e6 e 0000:000002ea. Então, vamos analisar estas duas operações:
select [Current LSN], Operation, [AllocUnitName], [Lock Information], [Transaction ID], [Description], [Begin Time], [Transaction Name], [Transaction SID] from fn_dblog(null, null) where [Transaction ID] = N'0000:000002e6';
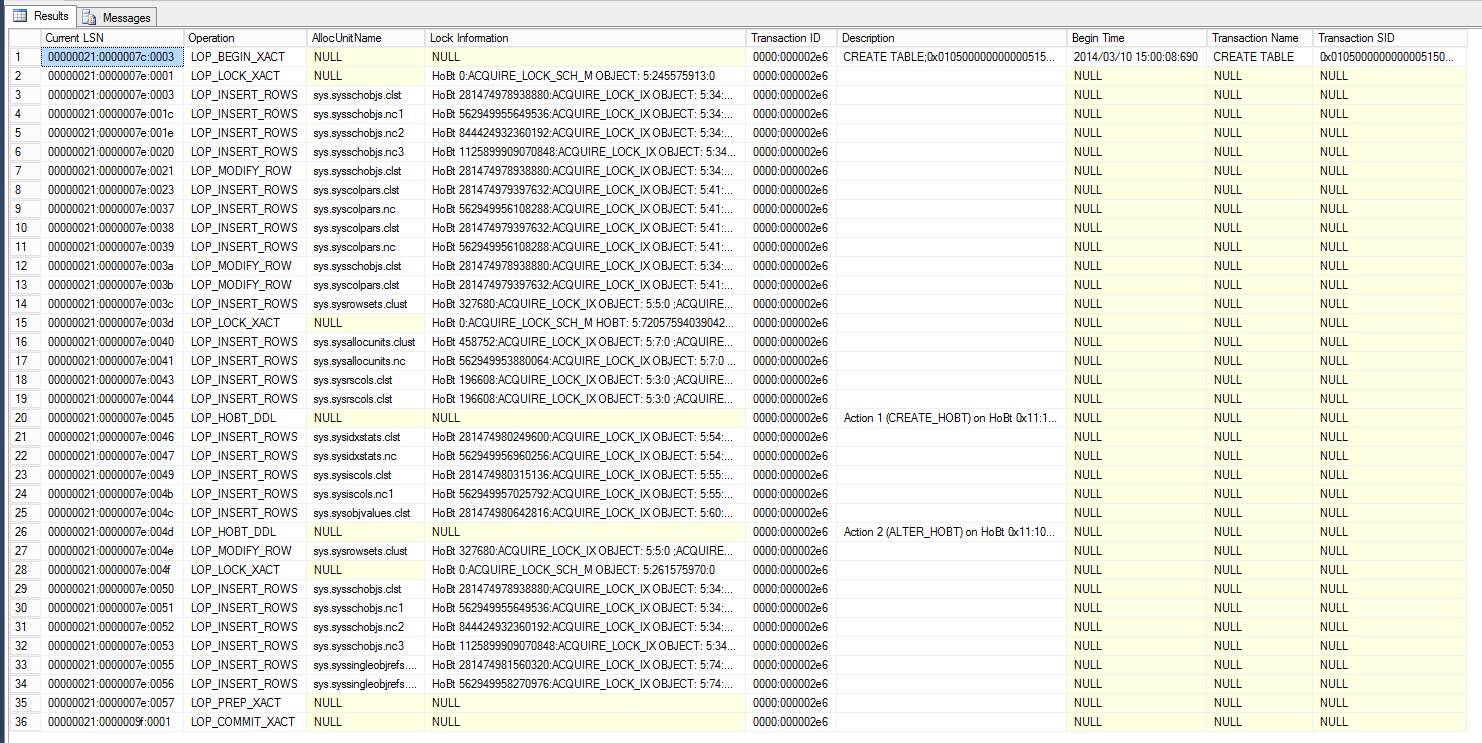
O primeiro ponto que deve ser notado é a transação do LOP_BEGIN_XACT, que contém o nome da operação DDL: CREATE TABLE. Adicione a data e o Transaction SID e encontramos no log o momento no qual a tabela foi criada e por quem. Usando as informações sobre tabelas de base do sistema, o restante das operações para essas transações pode ser interpretado:
Primeiros LOP_INSERT_ROWS em sys.sysschobjs.clst
Esta é a inserção do registro de objeto em sys.objects. Há quatro registros de inserção porque existe um índice agrupado e quatro índices não agrupados na tabela do catálogo syssysschobjs.
LOP_INSERT_ROWS em sys.syscolpars.clst
Estes são dois tipos de INSERT na coluna sys.columns. Cada um tem dois registros, um para o índice agrupado e um para o índice não agrupado.
LOP_INSERT_ROWS em sys.sysidxstats.clst
Esta é a inserção em sys.indexes.
LOP_INSERT_ROWS em sys.sysiscols.clst
Esta é a inserção em sys.index_columns.
Segundo LOP_INSERT_ROWS em sys.sysschobjs.clst
Esta é uma inserção em sys.objects de um objeto relacionado para a tabela, mas não a própria tabela. Nesse caso, é a restrição de chave primária, mas identificar esse tipo de informação é geralmente complicado. A melhor abordagem é simplesmente usar a instrução cast([RowLog Contents 0] as nchar(4000)) e procurar por alguma string que um humano possa ler, que seria o nome do objeto inserido, por exemplo. No meu caso, o conteúdo do registro de log revelou a cadeia PK__test__3213E83F1364FB13, então eu poderia facilmente deduzir que é o padrão chamado restrição de chave primária.
Como vimos, não recuperei exatamente o DDL que rodou, mas tenho uma ideia muito boa sobre o que aconteceu: a tabela foi criada em 2014/03/10 às 15:00:08:690, e inicialmente continha duas colunas e uma restrição de chave primária. Usando o mesmo truque de lançar o conteúdo do registro de log para NCHAR (4000), eu poderia facilmente recuperar os nomes das colunas originais. Meu exemplo ilustra uma forma muito simples de utilizar a instrução CREATE TABLE – declarações mais complexas podem gerar assinaturas de registro ainda mais complexas. O particionamento, em especial, adiciona uma infinidade de registros LOP_INSERT_ROWS porque cada partição individual deve ser descrita em sys.sysrowsets, e cada coluna para cada partição e para cada índice deve ser descrita em sys.sysrscols, e isso deve ser feito antes que os metadados sejam escritos; veja o documento as colunas da tabela SQL Server sob o capô.
Em seguida, vamos verificar a segunda transação, 0000:000002ea:
select [Current LSN], Operation, [AllocUnitName], [Lock Information], [Transaction ID], [Description], [Begin Time], [Transaction Name], [Transaction SID] from fn_dblog(null, null) where [Transaction ID] = N'0000:000002ea';
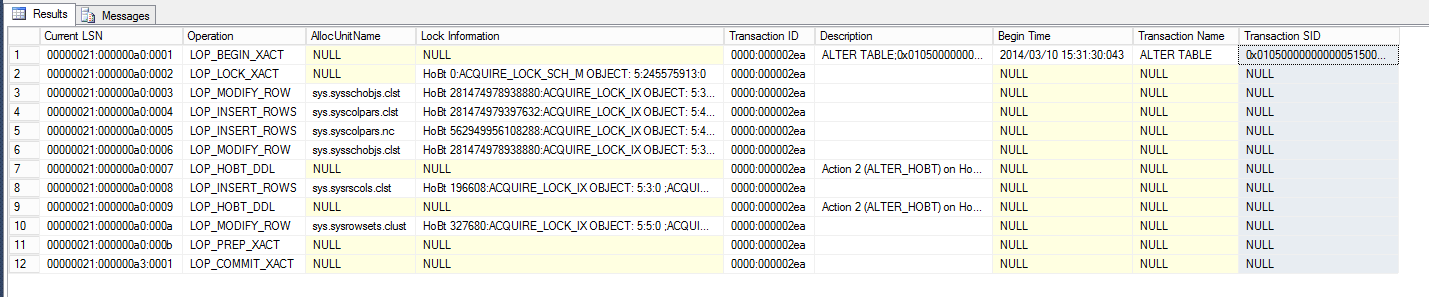
Mais uma vez, podemos ver o nome da transação que revela o tipo de operação DDL (nesse caso, é ALTER TABLE), a data e o horário em que ocorreu, e o SID do usuário que emitiu a mudança. Os LOP_INSERT_ROWS em sys.syscolpars.clst me dizem que esta é uma mudança DDL que acrescentou uma coluna à tabela.
Recuperando um Object ID suprimido
Como fazer quando estamos investigando um objeto que foi abandonado? Nós não podemos usar o truque do N ‘% SCH% <object id>%’ porque não sabemos o ID do objeto. Nesse caso, o que podemos fazer é verificar o registro LOP_DELETE_ROWS que excluiu os sys.objects dos objetos do formulário. Sabemos como isso vai afetar a unidade de alocação do sys.sysschobjs.clst e sabemos o nome do objeto excluído que deve estar no registro de log. No meu caso, estou procurando uma tabela que desapareceu e que foi chamada de ‘test’:
select [Current LSN], Operation, [AllocUnitName], [Lock Information], [Transaction ID], [Description], [Begin Time], [Transaction Name], [Transaction SID] from fn_dblog(null, null) where [Operation] = N'LOP_DELETE_ROWS' and [AllocUnitName] = N'sys.sysschobjs.clst' and CHARINDEX(cast(N'test' as varbinary(4000)), [Log Record]) > 0;

Encontramos dois registros da transação 0000:000002ee. Não deveria ser uma surpresa, pois há duas operações de exclusão, afinal o CREATE fez dois INSERT por conta da restrição de chave primária. Então, vamos olhar para operação 0000:000002ee:
select [Current LSN], Operation, [AllocUnitName], [Lock Information], [Transaction ID], [Description], [Begin Time], [Transaction Name], [Transaction SID] from fn_dblog(null, null) where [Transaction ID] = N'0000:000002ee';
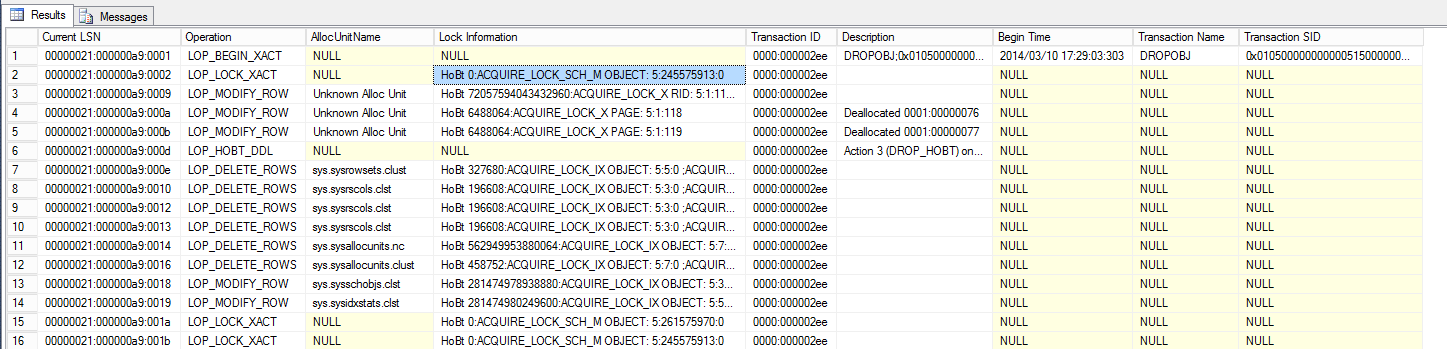
Mais uma vez temos o tempo da transação, o usuário que emitiu o DROP e o nome da transação DROPOBJ. Observe as operações LOP_LOCK_XACT que são registradas logo após o início da transação: HoBt 0: ACQUIRE_LOCK_SCH_M OBJETO: 5: 245575913: 0. Isso é importante, porque nos dá a identificação do objeto que foi criado no momento em que foi lançado. Usando esse ID de objeto, podemos procurar mais a fundo no registro e localizar outras alterações DDL, assim como mostrei acima.
É importante perceber que os IDs de objeto podem ser reciclados; depois que um objeto foi descartado, outro objeto pode ser criado usando o mesmo Object ID (acredite, isso pode acontecer). Portanto, preste atenção e certifique-se de que, quando seguir uma ID do objeto, você esteja procurando por registros de dados relevantes, não os registros de log de um objeto completamente desvinculado que por acaso reutilizou o mesmo Object ID. Lembre-se de que o registro de log LSN estabelece uma ordenação clara da data em que o evento foi criado para que seja mais simples descobrir o caso.
É também importante perceber que o CHARINDEX(cast(N’test’ as varbinary(4000)), [Log Record]) > 0 é uma condição que pode recuperar registros de log para DROP de outros objetos que contêm simplesmente a string ‘test’ em seu nome. Esse não é o único lugar onde algumas dessas técnicas podem falhar. Essas técnicas são bastante avançadas, o que não significa que os usuários as utilizem todos os dias. Espero que você utilize de bom senso. Tente corroborar as informações encontradas através de vários métodos.
***
Artigo traduzido pela Redação iMasters com autorização do autor. Publicado originalmente em http://rusanu.com/2014/03/10/how-to-read-and-interpret-the-sql-server-log/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?