

Na primeira parte deste artigo, mostrei algumas soluções para o problema dos relatórios que devem apresentar o valor zero quando não houver nenhuma transação num certo mês. Desta vez, eu vou analisar os planos de execução de cada uma das consultas.
Planos de execução são extremamente úteis e certamente são a principal fonte de informação para se avaliar e/ou comparar as performances de diferentes consultas. Eles indicam estimativas de consumo de CPU, memória e I/O de cada consulta. E apresentam também o custo de execução da consulta, que nada mais é do que uma combinação destes consumos.
O plano de execução de uma consulta é definido pelo otimizador de consultas do SGBD, que considera uma infinidade de variáveis antes de montá-lo. E por isso é muito complicado extrapolar a análise de um conjunto de planos para outro conjunto. De qualquer modo, é importante conhecer os métodos de comparação de planos de execução. E saber que algumas vezes eles nos reservam algumas surpresas, como se vê neste artigo.
Adaptando os planos de execução
Quando comecei este estudo, observei um detalhe desconcertante. O objetivo do estudo é comparar planos de execução de consultas que fazem junção de diferentes objetos (tabela física, CTE, tabela temporária e variável de tabela) com uma visão, chamada vwFaturamento.
Porém, nos testes iniciais, cada vez que eu rodava uma consulta, o SGBD montava um plano de execução diferente para a busca dos dados da visão vwFaturamento. Esse comportamento não é um “erro” do otimizador de consultas (veja Nota 1). Mas ele tornaria impossível a comparação das diferentes técnicas que apresentei no primeiro artigo desta série. Clique aqui para ver os planos de execução originais.
| NOTA 1: Por que os planos de execução da visão vwFaturamento eram diferentes? |
| Como eu mencionei anteriormente, o otimizador de consultas do SGBD avalia uma série de parâmetros antes de definir o plano de execução da consulta. Num ambiente de produção, algumas consultas são usadas com maior frequência que outras e as estatísticas de uso dos índices são atualizadas conforme este uso. Este nível de atividade vai influenciar a decisão do SGBD de manter ou não em cache o plano de execução das consultas.Porém todos os testes foram executados num ambiente de desenvolvimento, com praticamente nenhuma atividade relevante. Sendo assim, não havia nenhuma razão para que o SGBD mantivesse em cache um plano de execução qualquer. |
Para contornar este problema, decidi substituir a visão vwFaturamento por uma tabela tblFaturamento. Deste modo, qualquer variação no plano de execução de cada alternativa estudada seria devida à técnica considerada. A Listagem 1 mostra a criação da nova tabela. Para ver o script completo das consultas apontando para a nova tabela, clique aqui.
Listagem 1: criando a tabela tblFaturamento
-- criando a nova tabela e seu índice SELECT * INTO tblFaturamento FROM vwFaturamento GO CREATE INDEX ixFatMes ON tblFaturamento (mes, faturamento) GO
Outra adaptação que foi feita para nivelar as condições das quatro consultas pesquisadas foi reduzir a quantidade de registros da tabela tbListaMeses para os mesmos 24 registros (no caso, meses) usados nas outras três alternativas.
Observando os planos de execução
A seguir, temos os planos de execução reais das quatro consultas apresentadas e uma breve descrição deles.
Alternativa 1: variável de tabela
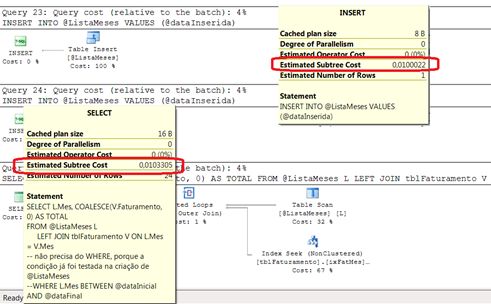
Observando a Figura 1 (que foi adaptada para mostrar o custo dos dois tipos de operação que aparecem neste plano), vemos que o plano começa com 24 operações de INSERT ao custo de 0,0100022 por operação. Em seguida, vemos uma operação de SELECT com custo de 0,103305. Portanto o custo total da consulta é a somatória dos custos das 25 operações, que resulta em 0,3433578 (ou seja, 24 * 0,0100022 mais 0,1033050).
Figura 1: plano de execução da Alternativa 1
Alternativa 2: tabela temporária
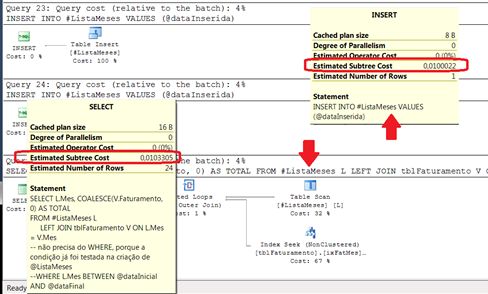
A Figura 2 mostra que a estrutura do plano de execução deste modelo é idêntica à da Alternativa 1 (Figura 1). São as mesmas 24 operações de INSERT seguidas de uma operação de SELECT, que novamente tem custo de 0,103305. Assim o custo total é novamente de 0,3433578.
Figura 2: plano de execução da Alternativa 2
Alternativa 3: tabela de expressão (CTE) recursiva
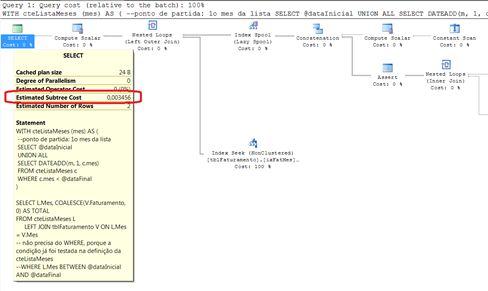
No caso da consulta usando a CTE recursiva, uma única operação é executada e o custo de preparação da CTE já está embutido no custo da consulta. O custo total é de 0,003456. Veja o plano na Figura 3.
Figura 3: plano de execução da Alternativa 3
Alternativa 4: tabela física com lista de meses
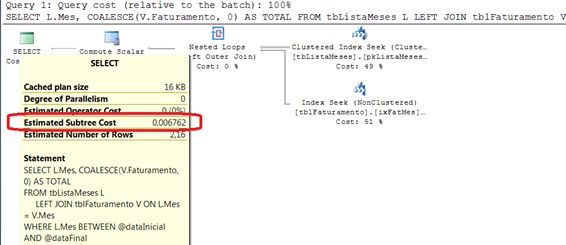
Nesta alternativa, a consulta é feita acessando uma tabela física (tbListaMeses), também ela com 24 registros. Ao contrário dos outros casos, não existe custo de preparação da tabela de meses, pelo simples fato de que é tabela física. Porém, existe um custo importante para pesquisa dos índices desta tabela, que presenta 49% do custo total da consulta (Veja Figura 4). O custo total é de 0,0067620.
Figura 4: plano de execução da Alternativa 4
Analisando resultados
A tabela 1 resume todos os números apresentados na seção anterior:
Tabela 1: Custo total do plano de execução das quatro alternativas avaliadas
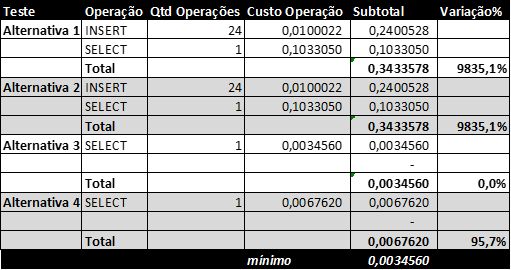
Aqui vemos que o menor custo é o da alternativa 3 (a CTE recursiva) e que os custos das alternativas 1 e 2 são a quase 100 vezes maior que o da consulta com CTE.
Vejamos mais alguns detalhes interessantes.
Alternativas 1 e 2
Estas duas alternativas têm exatamente o mesmo custo. Isso era esperado, porque a forma de implementação de tabelas temporárias e variáveis de tabela dentro do SQL Server é muita parecida.
Mas a Tabela 1 também mostra uma limitação séria das consultas que usam objetos temporários. Em primeiro lugar, eles requerem a inserção de registros, operação esta que tem um custo significativo e que cresce proporcionalmente conforme a quantidade de registros inseridos na tabela temporária. Nos testes em questão, houve 24 operações de INSERT e seu custo foi mais que o dobro do custo do SELECT! Obviamente o custo das operações de INSERT crescerá proporcionalmente ao número de registros inseridos no objeto temporário.
Em segundo lugar, o custo da operação de SELECT nas alternativas 1 e 2 sozinho já é maior que o custo da mesma operação nas alternativas 3 e 4. E espera-se que o custo desta operação cresça, caso se aumente o número de registros na tabela tblFaturamento ou mesmo no objeto temporário.
Estes números todos sugerem que o uso de objetos temporários tem performance ruim – o que pode ser agravado caso aumente o número de registros envolvidos.
Alternativa 3
O custo total da operação com CTE recursiva foi o melhor nos quatro testes realizados. Ele representa quase metade do custo do segundo colocado, operação com tabela física.
De certo modo, este resultado surpreende muita gente. CTEs são famosas por facilitar a leitura de consultas e, em alguns casos especiais – como o nosso, por oferecer recursividade às consultas. Mas é sabido que CTEs sempre causam uma pequena sobrecarga na consulta.
Estudando o plano de execução desta consulta mais a fundo (veja Figura 3), observei as seguintes características:
- O custo da operação INDEX SEEK na tabela tblFaturamento representa praticamente 100% do custo total da consulta;
- A soma de todas as operações para geração da CTE recursiva foi quase 0% (operações à direita do INDEX SPOOL da Figura 3);
- O custo da junção dos resultados das tabela e da CTE recursiva também ficou próximo de 0% (operação NESTED LOOPS também na Figura 3).
O que acontece aqui é que esta CTE recursiva está muito próxima da condição ótima de operação. Ela só lida com valores únicos, já que ela própria não é nada além de um contador (veja artigo de Tinline-Jones na seção de Referências).
Por sinal, eu repeti este teste para construção de uma CTE com 700 registros e o custo total da consulta continuou idêntico! Portanto, é de se esperar que a boa performance desta solução continue para qualquer relatório mensal que se deseje criar.
Como eu havia comentado no artigo anterior, “o maior problema da CTE recursiva é que o desenvolvedor precisa definir muito bem o critério de parada; do contrário, existe o risco de ela entrar em um laço infinito”. Este problema pode ser contornado definindo-se um valor default para o parâmetro MAXRECURSION, que é válido para toda instância. No SQL Server 2012, o valor default estabelece o máximo de 100 repetições da CTE Recursiva (veja o tópico “QUERY HINTS” no documento “Hints (Transact-SQL)”).
Apesar de esta solução apresentar a melhor performance de todas, há que se considerar que a sintaxe da CTE recursiva é pouco conhecida pela grande maioria dos desenvolvedores e isso é um risco quando pensamos na manutenção do código.
Alternativa 4
A solução com uma tabela física de meses (tbListaMeses) teve custo total de 0,0067620, o segundo melhor resultado dos testes.
O plano de execução desta consulta é composto de uma única instrução SELECT. Mas podemos ver na Figura 4 que praticamente 100% do custo se refere às pesquisas dos dados nas tabelas de faturamento e na lista de meses. As duas operações tem praticamente o mesmo custo (0,0034665 para a primeira e 0,0032844 para a segunda).
Fiz um novo teste com uma tabela de meses (tbListaMeses) com 700 registros e o custo subiu para 0,0123861. Ou seja, foi preciso aumentar a quantidade de registros 30 vezes para dobrar o custo da consulta. Isso é um bom resultado, pois demonstra que o custo não aumenta linearmente com a quantidade de registros de qualquer uma das tabelas.
Dada a combinação da boa performance, simplicidade da declaração SQL e a versatilidade que uma tabela de calendário pode oferecer, esta é a solução que eu escolheria para implementação. Qualquer pessoa seria capaz dar manutenção nesta declaração SQL. E com pequenas adaptações, é possível gerar relatórios por qualquer período de tempo desejado: dias, meses do calendário-safra ou calendário-fiscal, quartis, anos etc.
Conclusão
Os resultados obtidos aqui mostram, antes de tudo, que a performance das consultas usando objetos temporários é ruim. Esta característica somada ao problema do uso do TEMPDB (mencionado no artigo anterior) mostram que é preciso avaliar muito bem as características dos seus dados, as condições específicas da sua aplicação e também da sua instância antes de optar por uma solução usando objetos temporários.
Resultados mostram também que a escolha de uma das soluções propostas aqui depende também do conservadorismo do avaliador. DBAs são cautelosos por natureza e por isso recomendei a doação do método mais conservador possível: uso de tabela física. A solução é robusta, tem boa performance e é de fácil manutenção.
Finalmente, eu entendo que a conclusão mais importante deste artigo é sobre a aplicação do método de avaliação e não os resultados obtidos. Como eu disse, é muito difícil extrapolar resultados de performance para cenários diferentes daqueles em que os testes foram conduzidos. Por isso, é fundamental que o leitor entenda que a uniformização dos testes é tão importante quanto os resultados obtidos por eles.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?