

O sistema de armazenamento Schemaless da Uber Engineering alimenta alguns dos maiores serviços da Uber, como o Mezzanine. Schemaless é um datastore escalável e altamente disponível no topo do grupo de clusters do MySQL[1]. Gerenciar esses clusters foi bastante fácil quando tínhamos 16 deles. Atualmente, temos mais de 1.000 clusters contendo mais de 4.000 servidores de banco de dados e isso requer uma classe diferente de ferramentas.
Inicialmente, todos os nossos clusters eram gerenciados pelo Puppet, um monte de scripts ad hoc e operações manuais que não podiam escalar no ritmo da Uber. Quando começamos a procurar por uma melhor maneira de gerenciar o crescente número de clusters do MySQL, tivemos alguns requisitos básicos:
- Executar vários processos de banco de dados em cada host
- Automatizar tudo
- Possuir um único ponto de entrada para gerenciar e monitorar todos os clusters em todas as centrais de dados
A solução a que chegamos é um projeto chamado Schemadock. Executamos o MySQL em contêineres Docker, que são gerenciados por estados de objetivo que definem topologias de cluster em arquivos de configuração. As topologias de cluster especificam como os clusters do MySQL devem ser exibidos; por exemplo, que deve haver um Cluster A com 3 bancos de dados e qual deles deve ser o mestre. Agentes, então, aplicam essas topologias aos bancos de dados individuais. Um serviço centralizado mantém e monitora o estado de objetivo para cada instância e reage a quaisquer desvios.
O Schemadock tem muitos componentes, e o Docker é um pequeno, mas significativo deles. Mudar para uma solução mais escalável tem sido um esforço importante e este artigo explica como o Docker nos ajudou a chegar aqui.
Por que o Docker em primeiro lugar?
A execução de processos em contêiner facilita a execução de vários processos MySQL no mesmo host em diferentes versões e configurações. Isso também nos permite colocar pequenos clusters nos mesmos hosts para que possamos executar o mesmo número de clusters em menos hosts. Finalmente, podemos remover qualquer dependência em Puppet e ter todos os hosts ser provisionados na mesma função.
Quanto ao próprio Docker, os engenheiros agora constroem todos os nossos serviços sem estado no Docker. Isso significa que temos um monte de ferramentas e conhecimentos a respeito do Docker. O Docker não é perfeito, mas atualmente é melhor do que as alternativas.
Por que não usar o Docker?
As alternativas ao Docker incluem virtualização completa, contêineres LXC e o simples gerenciamento de processos MySQL diretamente nos hosts através, por exemplo, do Puppet. Para nós, a escolha pelo Docker foi bastante simples, uma vez que ele se encaixa em nossa infraestrutura existente. No entanto, se você ainda não estiver rodando Docker, fazê-lo para o MySQL já representará um projeto bastante grande: você precisa lidar com construção e distribuição de imagem, monitoramento, atualização do Docker, coleta de log, redes e muito mais.
Tudo isso significa que você realmente deve apenas usar Docker se você estiver disposto a investir bastante recursos nele. Além disso, o Docker deve ser tratado como uma peça de tecnologia, não como uma solução para acabar com todos os problemas. Na Uber, fizemos um projeto cuidadoso que tinha o Docker como um dos componentes em um sistema muito maior para gerenciar bancos de dados MySQL. No entanto, nem todas as empresas estão na mesma escala da Uber, e para elas uma configuração mais simples/honesta com algo como Puppet ou Ansible pode ser mais apropriada.
A imagem Docker Schemaless MySQL
Na base disso, nossa imagem do Docker apenas baixa e instala o Servidor Percona e inicia o mysqld – isso é mais ou menos como as imagens do Docker MySQL existentes lá fora. No entanto, entre download e início, uma série de outras coisas acontece:
- Se não houver dados existentes no volume montado, então sabemos que estamos em um cenário de bootstrap. Para um mestre, execute mysql_install_db e crie alguns usuários e tabelas padrão. Para um minion, inicie uma sincronização de dados do backup ou outro nó no cluster.
- Uma vez que o contêiner tenha dados, o mysqld será iniciado.
- Se qualquer cópia de dados falhar, o contêiner será desligado novamente.
A função do contêiner é configurada usando variáveis de ambiente. O que interessa aqui é que a função só controla como os dados iniciais são recuperados – a imagem do Docker por si mesma não contém nenhuma lógica para configurar topologias de replicação, verificação de status etc. Como essa lógica muda com muito mais frequência do que o próprio MySQL, faz bastante sentido separá-la.
O diretório de dados do MySQL é montado a partir do sistema de arquivos do host, o que significa que o Docker não introduz nenhuma sobrecarga de gravação. Nós, no entanto, transformamos a configuração MySQL em imagem, o que basicamente a torna imutável. Enquanto você pode alterar a configuração, ele nunca entrará em vigor devido ao fato de que nós nunca reutilizamos contêineres do Docker. Se um contêiner desligar por qualquer motivo, nós não o reiniciamos novamente. Excluímos o contêiner, criamos um novo a partir da imagem mais recente com os mesmos parâmetros (ou criamos novos, se o estado do objetivo foi alterado) e iniciamos esse.
Fazer isso dessa forma nos dá uma série de vantagens:
- O drift de configuração é muito mais fácil de controlar. Ele se resume a uma versão de imagem do Docker, que monitoramos ativamente.
- Atualizar o MySQL é uma questão simples. Construímos uma nova imagem e depois fechamos contêineres de forma ordenada.
- Se algo quebrar, nós apenas começamos tudo de novo. Em vez de tentar corrigir as coisas, apenas soltamos o que temos e deixamos o novo contêiner assumir.
A construção da imagem se dá através da mesma infraestrutura da Uber que opera serviços sem estado. A mesma infraestrutura replica imagens em bases de dados para disponibilizá-las nos registros locais.
Há uma desvantagem de executar vários contêineres no mesmo host. Como não há isolamento de I/O apropriado entre os contêineres, um contêiner pode usar toda a largura de banda de I/O disponível, o que deixa os contêineres restantes esfomeados. O Docker 1.10 introduziu cotas I/O, mas ainda não os experimentamos. Por agora, lidamos com isso não sobrescrevendo hosts e monitorando continuamente o desempenho de cada banco de dados.
Agendamento de contêineres Docker e configuração de topologias
Agora que temos uma imagem do Docker que pode ser iniciada e configurada como mestre ou minion, algo precisa realmente iniciar esses contêineres e configurá-los para as topologias de replicação corretas. Para fazer isso, um agente é executado em cada host do banco de dados. Os agentes recebem informações de estado de objetivo para todos os bancos de dados que devem estar sendo executados nos hosts individuais. Um típico estado de objetivo se parece com isto:
“schemadock01-mezzanine-mezzanine-us1-cluster8-db4”: {
“app_id”: “mezzanine-mezzanine-us1-cluster8-db4”,
“state”: “started”,
“data”: {
“semi_sync_repl_enabled”: false,
“name”: “mezzanine-us1-cluster8-db4”,
“master_host”: “schemadock30”,
“master_port”: 7335,
“disabled”: false,
“role”: “minion”,
“port”: 7335,
“size”: “all”
}
}
Isso nos diz que no host schemadock01 devemos executar um banco de dados minion Mezzanine na porta 7335, e ele deve ter o banco de dados executado em schemadock30: 7335 como mestre. Ele tem tamanho “all”, o que significa que é o único banco de dados executado nesse host. Portanto, ele deve ter toda a memória alocada a ele.
O modo como esse estado de objetivo é criado é um tópico para outro artigo, então vamos pular para as próximas etapas: um agente que está sendo executado no host o recebe, o armazena localmente e começa a processá-lo.
O processamento é na verdade um loop infinito que é executado a cada 30 segundos, similar a executar um Puppet cada 30 segundos. O ciclo de processamento verifica se o estado do objetivo corresponde ao estado real do sistema através das seguintes ações:
- Verifique se um contêiner já está em execução. Caso contrário, crie um com a configuração e inicie-o.
- Verifique se o contêiner tem a topologia de replicação correta. Se não, tente corrigi-lo.
- Se é um minion, mas que deveria ser um mestre, verifique se é seguro mudar para a função de mestre. Fazemos isso verificando se que o velho mestre é somente para leitura e se todos os GTIDs foram recebidos e aplicados. Quando esse é o caso, é seguro remover o link para o velho mestre e permitir gravações.
- Se for um mestre, mas que deveria estar desabilitado, ative o modo de somente leitura.
- Se é um minion, mas a replicação não está em execução, então configure o link de replicação.
- Verifique vários parâmetros do MySQL (read_only e super_read_only, sync_binlog etc.) com base na função. Os mestres devem ser graváveis, os minions devem ser read_only etc. Além disso, reduzimos a carga nos minions desligando binlog fsync e outros parâmetros similares[2].
- Inicie ou desligue quaisquer contêineres de suporte, como pt-heartbeat e pt-deadlock-logger
Notem que concordamos bastante com a ideia de contêineres de processo-único, de propósito-único. Dessa forma, não precisamos reconfigurar os contêineres em execução, e é muito mais fácil controlar as atualizações.
Se ocorrer um erro em qualquer ponto, o processo apenas gera um erro e aborta. Todo o processo é então repetido na próxima execução. Nos certificamos de ter alguma coordenação entre agentes individuais quanto possível. Isso significa que não nos importamos com a encomenda, por exemplo, ao provisionar um novo cluster. Se você estiver fornecendo manualmente um novo cluster, você provavelmente faria algo como isto:
- Crie o mestre do MySQL e espere que ele fique pronto
- Crie o primeiro minion e conecte-o ao mestre
- Repita para o minion restante
Claro, eventualmente algo como isso tem que acontecer. Entretanto, o que não nos importa é a ordenação explícita. Vamos apenas criar estados de objetivo que reflitam o estado final que queremos alcançar:
“schemadock01-mezzanine-cluster1-db1”: {
“data”: {
“disabled”: false,
“role”: “master”,
“port”: 7335,
“size”: “all”
}
},
“schemadock02-mezzanine-cluster1-db2”: {
“data”: {
“master_host”: “schemadock01”,
“master_port”: 7335,
“disabled”: false,
“role”: “minion”,
“port”: 7335,
“size”: “all”
}
},
“schemadock03-mezzanine-cluster1-db3”: {
“data”: {
“master_host”: “schemadock01”,
“master_port”: 7335,
“disabled”: false,
“role”: “minion”,
“port”: 7335,
“size”: “all”
}
}
Isso é empurrado para os agentes pertinentes em ordem aleatória, e todos eles começam a trabalhar nele. Para alcançar o estado de objetivo, uma série de tentativas pode ser necessária, dependendo do pedido. Geralmente, os estados de objetivo são alcançados em algumas tentativas, mas algumas operações podem realmente exigir centenas de tentativas. Por exemplo, se os minions começarem a processar primeiro, então não poderão se conectar ao mestre e terão que tentar mais tarde. Uma vez que pode levar um pouco de tempo para obter o mestre em funcionamento, os minions podem ter de repetir um monte de vezes:
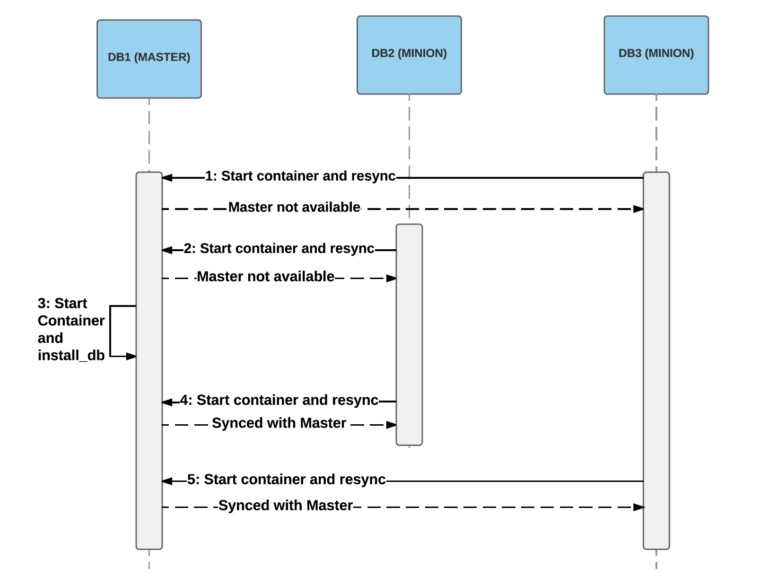 Um exemplo de 2 minions que se iniciam antes do mestre. Na inicialização inicial (etapas 1 e 2), os minions não conseguirão obter um snapshot do mestre, o que falhará o processo de inicialização. Em seguida, o mestre inicia na etapa 3, e os minions são capazes de conectar e sincronizar dados nas etapas 4 e 5.
Um exemplo de 2 minions que se iniciam antes do mestre. Na inicialização inicial (etapas 1 e 2), os minions não conseguirão obter um snapshot do mestre, o que falhará o processo de inicialização. Em seguida, o mestre inicia na etapa 3, e os minions são capazes de conectar e sincronizar dados nas etapas 4 e 5.
Experiência com o Docker Runtime
A maioria dos nossos hosts executa o Docker 1.9.1 com devicemapper no LVM para armazenamento. Usar o LVM para devicemapper acabou por executar significativamente melhor do que devicemapper no loopback. devicemapper teve muitos problemas com desempenho e confiabilidade, mas alternativas como AuFS e OverlayFS também apresentaram muitos problemas[3]. Isso significa que tem havido muita confusão na comunidade sobre a melhor opção de armazenamento. Até agora, OverlayFS está ganhando muita tração e parece ter estabilizado, então vamos mudar para ele e também atualizar para o Docker 1.12.1.
Um dos pontos dolorosos de atualizar Docker é que isso requer um reiniciar, que também reinicia todos os contêineres. Isso significa que o processo de atualização tem que ser controlado para que não tenhamos mestres em execução quando atualizarmos um host. Esperançosamente, o Docker 1.12 será a última versão em que nós teremos de nos preocupar com isso; a versão 1.12 tem a opção de reiniciar e atualizar o daemon do Docker sem precisar reiniciar os contêineres.
Cada versão vem com muitas melhorias e novos recursos, introduzindo um número razoável de bugs e regressões. A versão 1.12.1 parece melhor do que as versões anteriores, mas ainda enfrentamos algumas limitações:
- docker inspect trava às vezes após o Docker ter sido executado por alguns dias.
- Usar ponte de rede com userland proxy resulta em um comportamento estranho em torno da terminação de conexão TCP. Por vezes, as ligações do cliente nunca recebem um sinal RST e permanecem abertas, independentemente do tipo de limite de tempo que você configure.
- Processos de contêiner são ocasionalmente reparados em pid 1 (init), o que significa que o Docker perde o controle deles.
- Nós regularmente vemos casos em que o daemon do Docker leva muito tempo para criar novos contêineres.
Resumo
Nós delimitamos alguns requisitos para gerenciamento de cluster de armazenamento na Uber:
- Múltiplos contêineres em execução no mesmo host
- Automação
- Um único ponto de entrada
Agora, podemos realizar a manutenção do dia a dia através de ferramentas simples e uma UI única, nenhuma delas exigindo acesso direto ao host:

Captura de tela do nosso console de gerenciamento. A partir daqui, podemos seguir o progresso do estado do objetivo, neste caso em que estamos dividindo um cluster em dois, primeiramente adicionando um segundo cluster e, em seguida, cortando o link de replicação.
Nós podemos melhor utilizar nossos hosts executando múltiplos contêineres em cada um. Podemos fazer upgrades fleet-wide de forma controlada. Usando o Docker nos trouxe aqui rapidamente. O Docker também nos permitiu executar uma configuração completa de cluster localmente em um ambiente de teste e testar todos os procedimentos operacionais.
Iniciamos a migração para o Docker no começo de 2016 e agora estamos executando cerca de 1.500 servidores de produção Docker (apenas para MySQL) e provisionamos aproximadamente 2.300 bancos de dados MySQL.
Há muito mais no Schemadock, mas o componente Docker tem sido de grande ajuda para o nosso sucesso, permitindo-nos mover rapidamente e experimentar, enquanto também nos apropriamos da infraestrutura existente na Uber. Todo armazenamento de viagens, que recebe milhões de viagens todos os dias, agora é executado em bases de dados dockerizadas em MySQL juntamente com outros armazenamentos. O Docker tornou-se, em outras palavras, uma parte crítica das encantadoras viagens Uber.
[1] Para ser mais preciso, o Percona Server 5.6
[2] sync_binlog = 0 and innodb_flush_log_at_trx_commit = 2
[1] Uma pequena seleção de issues:
- https://github.com/docker/docker/issues/16653,
- https://github.com/docker/docker/issues/15629,
- https://developerblog.redhat.com/2014/09/30/overview-storage-scalability-docker/,
- https://github.com/docker/docker/issues/12738
***
Este artigo é do Uber Engineering. Ele foi escrito por Joakim Recht. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/dockerizing-mysql/.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?