

Se Protocol Buffers são a língua franca de registros de dados individuais no Google, então a Sorted String Table (SSTable) é uma das saídas mais comuns para armazenar, processar e trocar conjuntos de dados. Como o próprio nome diz, uma SSTable é uma abstração simples para armazenar eficientemente um grande número de pares de chave-valor ao mesmo tempo em que se prioriza uma alta velocidade de saída (throughput) em cargas de trabalho sequenciais de leitura e escrita.
SSTable: Sorted String Table
Imagine que precisamos de uma enorme carga de trabalho na qual a entrada é feita em Gigabytes ou Terabytes. Além disso, precisamos realizar muitos passos de processamento, que precisam ser feitos por diferentes binários – em outras palavras, imagine que estamos executando uma sequência de tarefas de Map-Reduce! Dado o tamanho do input, ler e escrever dados pode dominar todo o tempo de execução. Portanto, leituras e escritas aleatórias não são uma opção; em vez disso, queremos transmitir os dados e, uma vez que terminarmos, gravamos de volta no disco como uma operação de streaming. Dessa forma, podemos amortizar os custos de I/O de disco. Nada revolucionário, ou longe disso.

Uma “Sorted String Table” (Tabela Ordenada de Palavras, em tradução livre) é exatamente o que parece, um arquivo que contém uma série de pares de chave-valor ordenados de forma arbitrária. Chaves duplicadas não são um problema, pois não há a necessidade de preenchimento de chaves ou valores, e chaves e valores são partículas arbitrárias. Leia todo o arquivo sequencialmente, e você terá uma espécie de índice. Opcionalmente, se o arquivo for muito grande, podemos incluir no início ou criar um índice key:offset separado para acesso rápido. Isso é tudo que uma SSTable é: uma forma muito simples, mas também muito útil, de trocar grandes porções de dados ordenados.
SSTable e BigTable: alta velocidade de acesso?
Uma vez que a SSTable estiver no disco, será na verdade imutável, porque inserir ou deletar dados demandaria uma grande quantidade de reescrita de I/O no arquivo. Tendo dito isso, ela é uma ótima solução para índices estáticos: leia o índice, e você estará sempre a uma busca de distância, ou simplesmente memmap (mapeie) todo o arquivo para a memória. Leituras aleatórias são fáceis e rápidas.
Escritas, por outro lado, são muito mais custosas e difíceis, a não ser que toda a tabela esteja na memória, o que, nesse caso, significa estarmos de volta à simples manipulação de ponteiros. Acontece que este é o grande problema que o BigTable do Google tenta resolver: altas taxas de leitura/escrita para petabytes de dados, com SSTables na retaguarda. Como eles fazem isso?
SSTables e Log Structured Merge Trees
Queremos preservar as altas taxas de leitura que as SSTables nos oferecem, mas também queremos altas taxas de escrita. Acontece que já temos todos os pedaços necessários: escrita aleatória é mais rápida quando a SSTable está na memória (vamos chamá-la de MemTable) e, se a tabela é imutável, então uma SSTable no disco também é rápida para ser lida. Agora vamos introduzir as seguintes convenções:
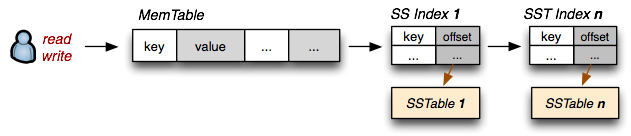
- Índices de SSTables no disco são sempre carregados para a memória
- Todas as operações de escrita vão diretamente para os índices da MemTable
- Leituras checam a MemTable primeiro e então consultam o índice da SSTable
- Periodicamente, a MemTable é gravada no disco como uma SSTable
- Periodicamente, SSTables no disco são unidas.
O que fizemos aqui? Escritas são sempre feitas na memória e por isso são sempre mais rápidas. Uma vez que a MemTable atinge um certo tamanho, ela é gravada no disco como uma SSTable imutável. De qualquer maneira, manteremos todos os índices da SSTable na memória, o que significa que para qualquer leitura poderemos checar primeiro na MemTable, e então seguir a sequência da SSTable para encontrar os nossos dados. O resultado é que acabamos de reinventar o “Log-Structured Merge-Tree” (LSM Tree), descrito por Patrick O’Neil, e esse é exatamente o mesmo mecanismo por trás das “Tabelas BigTable”.
LSM e SSTables: apagar, atualizar e manutenção
Essa arquitetura “LSM” oferece algumas características interessantes: operações de escrita são sempre rápidas, independentemente do tamanho dos dados (append-only), e operações de leitura aleatórias ou são feitas a partir da memória ou necessitam de uma rápida busca em disco. De qualquer forma, e quanto a atualizações e exclusões?
Uma vez que a SSTable está no disco, ela é imutável, portanto atualizações e exclusões não podem tocar os dados. Em vez disso, no caso de uma atualização ocorrer, um valor mais recente é simplesmente armazenado na MemTable, e um registro de “mortos” é acrescentado para as exclusões. Porque os índices são checados na sequência, leituras futuras irão encontrar o registro de mortos atualizado antes mesmo de atingirem os valores antigos! Finalmente, ter centenas de SSTables em disco também não é uma boa ideia, e por isso vamos executar periodicamente um processo para fundir as mudanças nas SSTables, momento em que os registros atualizados ou removidos atualizarão os dados antigos.
SSTables e LevelDB
Pegue uma SSTable, acrescente uma MemTable e aplique uma série de convenções de processamento e o que você terá será uma bela base de dados para certos tipos de trabalhos. Na verdade, tanto o Big Table do Google, quanto o Hbase do Haddop e o Cassandra, entre outros, estão utilizando uma variação ou cópia idêntica dessa mesma arquitetura.
Isso superficialmente, pois, como de costume, detalhes de implementação fazem toda a diferença. Graças a Jeff Dean e a Sanjay Ghemawat, os contribuintes originais da SSTable e da infraestrutura do Big Table no Google, o código fonte do LevelDB foi liberado no início do ano passado, que é mais ou menos uma réplica exata da arquitetura que descrevemos acima:
- SSTables embaixo do capô, MemTables para escritas
- Chaves e valores são arrays de bytes arbitrários
- Suporte para operações de Put, Get e Delete
- Iteração forward e backward de dados
- Compressão Snappy embutida
Projetado para ser o melhor mecanismo de IndexDB no WebKit (também conhecido como “no navegador”), ele é fácil de integrar, rápido e, o melhor de tudo, cuida de toda a gravação de SSTable e MemTable, merging e outros detalhes inconvenientes.
Trabalhando com LevelDB: Ruby
LevelDB é uma biblioteca, não um servidor ou serviço independente – apesar de você poder implementar um facilmente sobre ele. Para começar, pegue o binding da sua linguagem favorita (ruby) e vamos ver o que podemos fazer:
require 'leveldb' # gem install leveldb-ruby db = LevelDB::DB.new "/tmp/db" db.put "b", "bar" db.put "a", "foo" db.put "c", "baz" puts db.get "a" # => foo db.each do |k,v| p [k,v] # => ["a", "foo"], ["b", "bar"], ["c", "baz"] end db.to_a # => [["a", "foo"], ["b", "bar"], ["c", "baz"]]
Podemos armazenar chaves, recuperá-las, e realizar pesquisas com apenas algumas linhas de código. A mecânica de manter uma MemTable, atualizar SSTables, e todo o resto fica por conta do LevelDB – fácil e simples.
LevelDB no WebKit e além
SSTables são estruturas de dados bastante simples e úteis – um belo formato de entrada/saída de larga escala. Entretanto, o que torna as SSTables rápidas (ordenadas e imutáveis) é também o que expõe suas muitas limitações. Para resolver isso, introduzimos o conceito de MemTable e um conjunto de “estruturas de processamento de log” para administrar as SSTables.
São regras simples, mas, como sempre, detalhes de implementação fazem toda a diferença, o que torna o LevelDB um grande ganho para o conjunto de mecanismos de bases de dados de código aberto. Há boas chances de que você vá se deparar com o LevelDB embutido no seu navegador, no seu aparelho de telefone e em outros lugares. Dê uma olhada no código fonte do LevelDB, leia a documentação e experimente.
***
Artigo traduzido pela Redação iMasters, com autorização do autor. Publicado originalmente em http://www.igvita.com/2012/02/06/sstable-and-log-structured-storage-leveldb/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?