

Resumo: Construir a melhor experiência de viagem para os nossos clientes na Booking.com muitas vezes envolve a resolução de problemas muito difíceis. Um que aparece com muita frequência é o problema do K-vizinho mais próximo (k-Nearest Neighbours (k-NN)). Simplificando, ele pode ser declarado como o seguinte: dada uma coisa, encontrar k coisas mais semelhantes. Dependendo de como a coisa semelhante é definida, o problema torna-se mais ou menos complexo. Neste artigo, de duas partes, vamos tratar o caso em que as coisas são representadas por vetores, e à semelhança das duas coisas é definida pelo seu ângulo. Vamos discutir soluções e apresentar um truque prático para tornar isso rápido, escalável e simples. Tudo isso, graças à matemática. Confira a primeira parte aqui.
O truque k-NN
O objetivo desse truque é encontrar uma maneira de ser capaz de usar similaridade do cosseno com uma Space Partitioning Tree, que nos daria O(logn) complexidade de tempo, o que é uma grande melhoria.
A ideia é realmente muito simples: como a similaridade do cosseno é invariante sob a normalização, nós podemos apenas normalizar todos os nossos vetores de características e os k-vizinhos mais próximos a X serão exatamente os mesmos; mas agora os nossos vetores são todos vetores unitários, o que significa que classificá-los pela distância do cosseno de X é exatamente o mesmo que classificá-los pela distância euclidiana de X, e como a distância euclidiana é uma métrica adequada, podemos usar uma Space Partitioning Tree e desfrutar do logaritmo de n. Aqui está a receita:
- Normalize todas as características dos vetores no banco de dados
- Crie uma Space Partitioning Tree usando os vetores normalizados
- Quando os k vizinhos mais próximos para um vetor de entrada X são solicitados: normalize X e procure o k-NN da Space Patitioning Tree
6 – Experimentos
A experimentação está no núcleo de desenvolvimento de produto da Booking.com. Toda ideia é bem-vinda, se transforma em uma hipótese e é validada através de experimentação. E a Ciência de Dados não escapa desse processo.
Nesse caso, a ideia foi completamente descrita e apoiada com exemplos práticos e até mesmo matemática. Mas vamos ver se a realidade concorda com o nosso entendimento. A nossa hipótese é a seguinte: podemos melhorar o tempo de resposta do algoritmo descrito na seção 2, aplicando o truque descrito na seção 5 garantindo exatamente os mesmos resultados.
Para testar essa hipótese, foi concebido um experimento que compara o tempo necessário para resolver o problema k-NN usando a solução de varredura completa com o tempo necessário para a solução do truque k-NN. O truque k-NN é implementado usando duas Space Partitioning Trees diferentes: Ball Tree e KD-Tree.
O banco de dados consiste em imagens de dígitos manuscritos do MNIST. Para n variando de 5.000 a 40.000 com amostra aleatória de n imagens do banco de dados original; então são aplicadas as diferentes soluções para a mesma amostra, calculando as 10 imagens mais similares para 20 imagens de entrada.
7 – Resultados
Os resultados da nossa experiência estão resumidos na Figura 4:
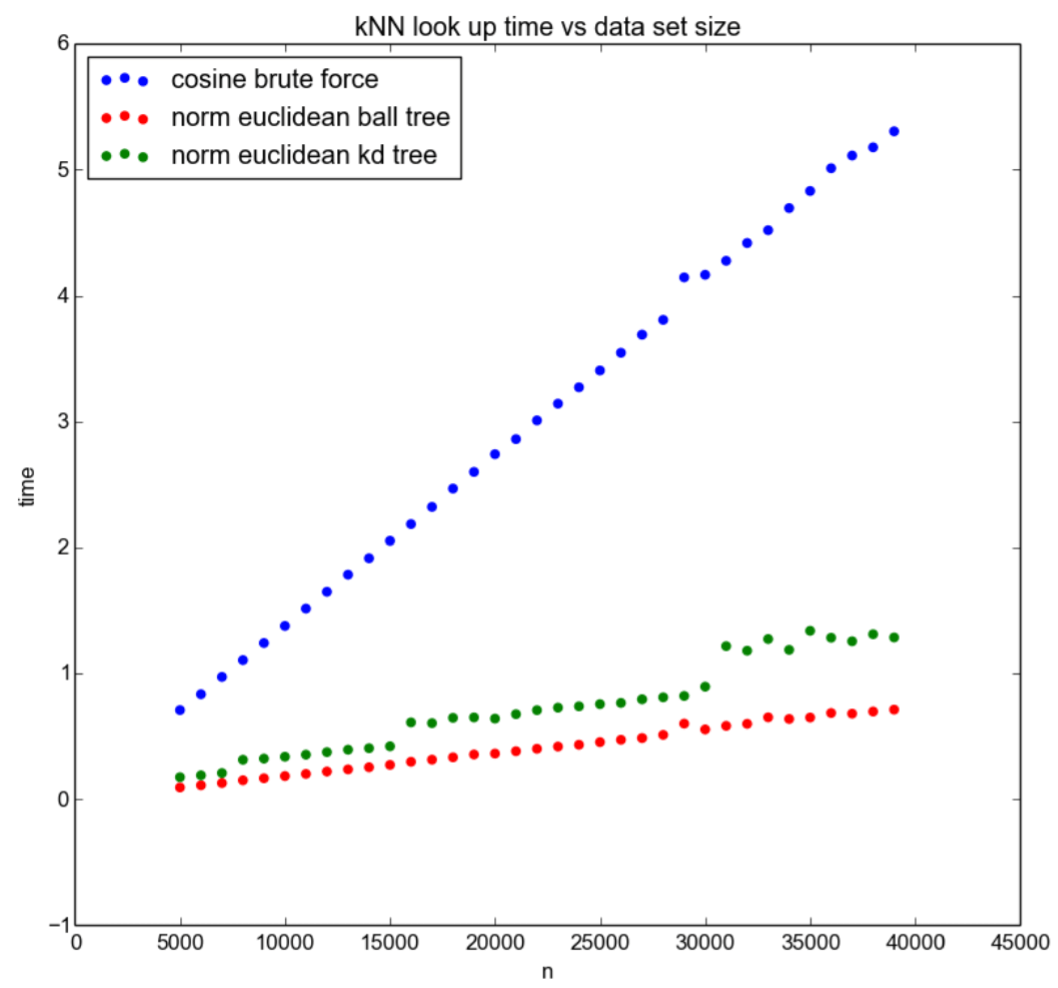 Fig 4: Comparação da solução completa de digitalização (força bruta) e o truque k-NN (norma da euclidiano ball tree, e kd tree) para o banco de dados de diferentes tamanhos de n
Fig 4: Comparação da solução completa de digitalização (força bruta) e o truque k-NN (norma da euclidiano ball tree, e kd tree) para o banco de dados de diferentes tamanhos de n
A partir do gráfico, podemos tirar várias conclusões: em primeiro lugar, a complexidade de tempo da solução de varredura completa é realmente linear em n, como sugerido pelos pontos azuis. Isso confirma a análise teórica na seção 2. Em segundo lugar, embora seja difícil dizer se a solução baseada no truque k-NN seja logarítmica, é claramente muito melhor do que a varredura completa, como sugerem os pontos verdes e vermelhos. Em terceiro lugar, a solução baseada em Ball Tree é melhor do que a solução KD-Tree, embora a razão para esse fato não esteja clara e requer uma análise mais aprofundada e experimentação. No geral, a experiência apoia fortemente a hipótese.
8 – A armadilha
Cada truque configura uma armadilha, e cada ganho em um aspecto esconde uma perda em outro. Estar ciente dessas armadilhas é a chave para aplicar com êxito esses truques. Vamos ver que armadilha o truque do k-NN arma, ou, nas palavras mais técnicas, com que tipo de trade-off estamos lidando?
Na solução simples, antes de ser capaz de responder a uma consulta k-NN, tudo o que precisamos fazer é calcular os vetores de características de cada objeto no banco de dados. Por outro lado, ao usar o truque, antes de sermos capazes de responder a uma consulta, não só precisamos calcular os vetores de características, mas também precisamos construir a Space Partitioning Tree. No experimento que executamos, nós também registramos o tempo que leva para sermos capazes de responder a consultas. Os resultados são apresentados na Figura 5 e mostram que as soluções à base do truque escalam muito pior do que a solução mais simples. Isso significa que, ao usar o truque, estamos trocando tempo de resposta de consulta com o tempo de início.
Esse trade-off deve ser tomado com cuidado e, para bancos de dados grandes, isso pode ter consequências muito negativas. Considere um site de e-commerce que sai do ar por qualquer motivo; imagine que esse e-commerce utiliza k-NN para servir algumas recomendações (uma parte muito importante, mesmo que não crítica, do sistema). Assim que resolvermos o problema, queremos que o sistema reinicie o mais rápido possível, mas se o processo de inicialização depende do sistema k-NN, caímos na armadilha – os usuários não serão capazes de comprar qualquer coisa até que nossa Space Partitioning Tree seja construída. Nada bom.
Isso pode ser facilmente resolvido quebrando a dependência, usando processos paralelos ou assíncronos para iniciar diferentes partes do sistema, mas a solução simples é claramente mais robusta nesse caso, até um ponto em que nem sequer é preciso se preocupar. O truque k-NN nos obriga a considerar isso com muito cuidado e agir adequadamente. Para muitas aplicações, esse não é um mau preço a ser pago pela velocidade e escalabilidade que teremos no momento da consulta.
9 – Conclusão
Neste artigo de duas partes, foi descrito um truque para acelerar a solução padrão para o problema k-NN com similaridade do cosseno. A lógica matemática para o truque foi apresentada, bem como experimentos que provam a sua validade. Nós consideramos isso como um bom exemplo de um problema de escalabilidade que podemos superar através da aplicação de matemática elementar. Este é também um bom exemplo de reducionismo: o truque é uma redução do problema de similaridade do cosseno k-NN para um problema de distância euclidiana k-NN, que é um problema muito mais estudado e resolvido. Matemática e reducionismo são dois conceitos que ficam no cerne da Ciência de Dados aplicada na Booking.com, sempre ao serviço da melhor experiência de viagem.
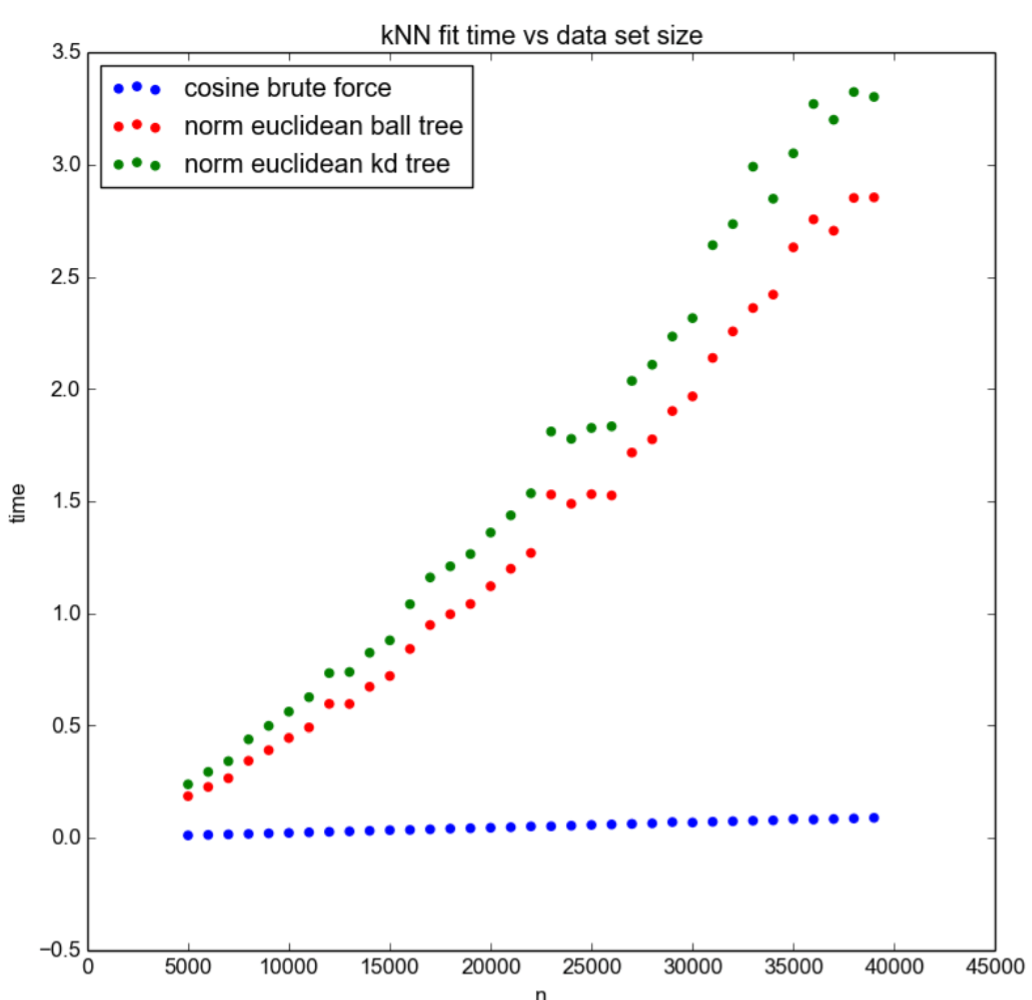 Fig 5: Tempo de preparo da comparação da solução de verificação completa e do truque k-NN para banco de dados de diferentes tamanhos n
Fig 5: Tempo de preparo da comparação da solução de verificação completa e do truque k-NN para banco de dados de diferentes tamanhos n
***
Lucas Bernardi faz parte do time de colunistas internacionais do iMasters. O artigo foi publicado originalmente em Booking.com. A tradução do artigo é feita pela redação iMasters, com autorização do autor, e você pode acompanhar o artigo em inglês no link: http://blog.booking.com/k-nearest-neighbours-from-slow-to-fast-thanks-to-math.html. Se tiver alguma pergunta, entre em contato pelo Twitter (@planetbooking).

De 0 a 10, o quanto você recomendaria este artigo para um amigo?