

Resumo: Construir a melhor experiência de viagem para os nossos clientes na Booking.com muitas vezes envolve a resolução de problemas muito difíceis. Um que aparece com muita frequência é o problema do K-vizinho mais próximo (k-Nearest Neighbours (k-NN)). Simplificando, ele pode ser declarado como o seguinte: dada uma coisa, encontrar k coisas mais semelhantes. Dependendo de como a coisa semelhante é definida, o problema torna-se mais ou menos complexo. Neste artigo, de duas partes, vamos tratar o caso em que as coisas são representadas por vetores, e à semelhança das duas coisas é definida pelo seu ângulo. Vamos discutir soluções e apresentar um truque prático para tornar isso rápido, escalável e simples. Tudo isso, graças à matemática.
1 – Coisas e semelhança
Suponha que nos é dado um banco de dados com fotos de dígitos escritos à mão, e a tarefa de encontrar caligrafia semelhante a esses dígitos. Cada imagem contém exatamente um dígito, mas não sabemos qual. Para cada imagem dada queremos, encontrar outras fotos que contêm o mesmo dígito escrito com um estilo semelhante.
Em primeiro lugar, temos de encontrar uma representação para as imagens que podemos usar para operar. Nesse caso, será um simples vetor, o comprimento d do vetor é o número de pixels na imagem, e os componentes são os valores RGB dos pixels. Essa representação tem a vantagem de trabalhar tanto no nível computacional quanto no da matemática.
Em segundo lugar, precisamos definir similaridade. Como as imagens são representadas por vetores, podemos calcular o ângulo entre quaisquer dois deles; se o ângulo é pequeno, os vetores apontam na mesma direção e as imagens são semelhantes. Por outro lado, se o ângulo for grande, os vetores divergem uns dos outros e as imagens não são semelhantes. Mais formalmente, a semelhança entre as duas imagens representadas por vetores X e Y é dada por:
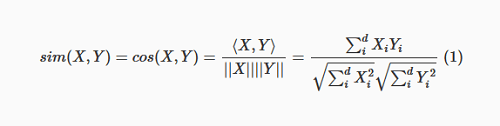
Essa quantidade tem uma propriedade muito boa: nunca será mais do que 1 ou menos que -1. Dados dois vetores, se a sua semelhança for próxima de 1, então eles são muito semelhantes; se ela está perto de -1, eles são completamente diferentes. 0 está no meio – não é muito semelhante, mas não completamente diferente.
Vamos ver isso em ação:
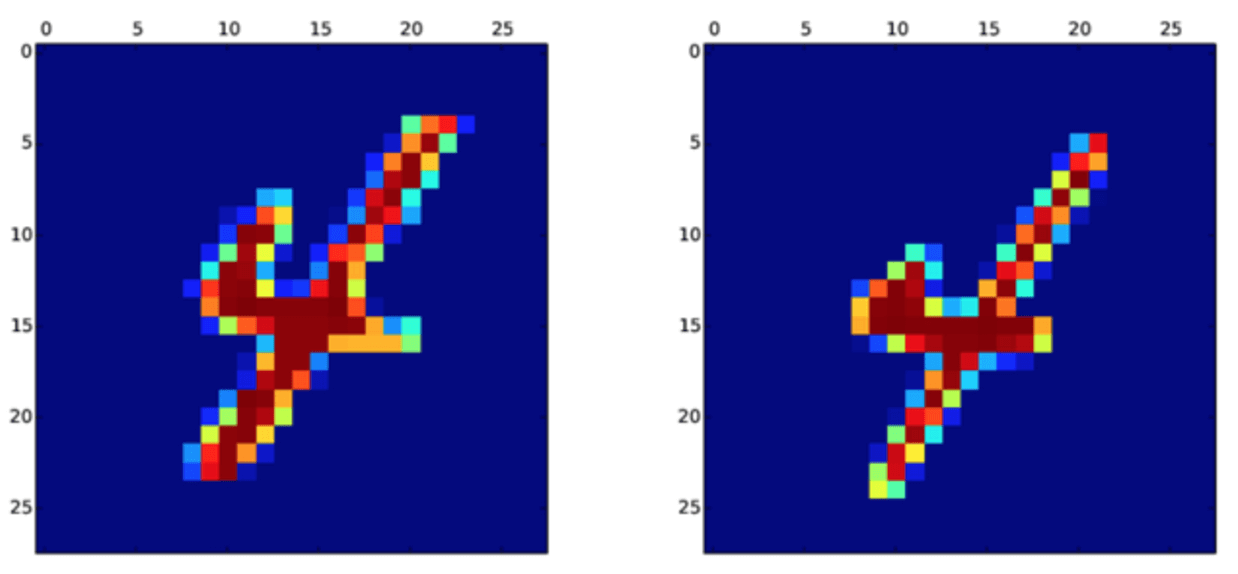 Fig. 1: Dois números 4 muito semelhantes; a sua semelhança de acordo com a equação 1 é de 0.85
Fig. 1: Dois números 4 muito semelhantes; a sua semelhança de acordo com a equação 1 é de 0.85
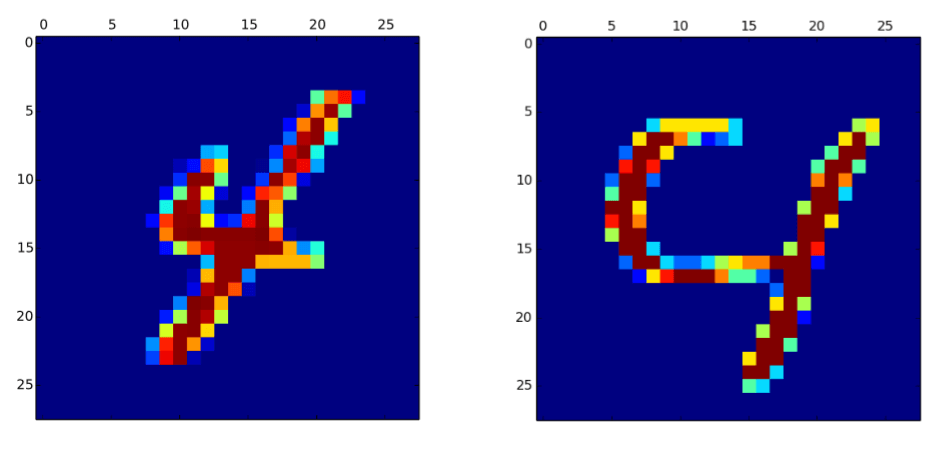 Fig. 2: Duas números 4 muito diferentes; a sua semelhança de acordo com a equação 1 é de 0.11
Fig. 2: Duas números 4 muito diferentes; a sua semelhança de acordo com a equação 1 é de 0.11
A figura 1 mostra uma representação gráfica dos vetores calculada a partir de duas imagens de dígitos escritos à mão. Esses dois dígitos são muito semelhantes, e quando a semelhança é calculada por seu ângulo usando a equação 1, dá 0.85, o que é, por conseguinte, bastante elevado. Por outro lado, a figura 2 mostra dois números bastante diferentes; dessa vez, sua semelhança é de 0.11, o que é bastante baixo, mas ainda positivo – mesmo que o estilo de escrita seja muito diferente, ambas as imagens são ainda um 4.
Essas imagens foram escolhidas a dedo para ilustrar a representação vetorial e a similaridade do cosseno. Vamos agora passar a encontrar um algoritmo que encontra dígitos manuscritos semelhantes.
2 – Uma solução simples
Agora que sabemos como representar coisas e calcular sua semelhança, vamos resolver o problema k-NN:
- Para cada imagem no nosso banco de dados, calcular o seu vetor associado.
- Quando os k mais próximos vizinhos para uma imagem são solicitados, calcular sua semelhança com qualquer outra imagem na base de dados.
- Classificar as fotos por similaridade ascendente.
- Devolver os últimos k elementos.
Essa é uma solução muito boa (especialmente porque ela funciona). A figura 3 mostra esse algoritmo em ação. Cada linha mostra as principais 9 imagens mais similares à primeira imagem na linha. A primeira linha captura números 3 muito arredondados, a segunda, 3 inclinados, a quarta linha mostra números 2 com um laço na parte inferior, e a quinta linha mostra Z como 2. Note que esse algoritmo não tem nenhuma informação sobre o dígito que está na imagem (nem qualquer coisa sobre que tipo de coisas a imagem tem), mas consegue agrupar por dígito, e até mesmo pelo estilo tipográfico.
Mas vamos dar uma olhada bem de perto através da análise de sua complexidade computacional. Considere n imagens com d pixels cada uma:
- Calculando um vetor de característica O(d). Como isso é feito para cada imagem, o primeiro passo é O(nd).
- A função de similaridade é O(d), e novamente isso acontece n vezes, em seguida, o segundo passo é também O(nd).
- O terceiro passo – ordenar n elementos – é O(nlogn).
- Finalmente retornando os últimos elementos k poderia ser constante, mas vamos considerar O(k).
No total, temos:
O(nd)+O(nd)+O(nlogn)+O(k) (2)
k é muito pequeno em comparação com n e d, então podemos negligenciar o último prazo. Nós também podemos recolher os dois primeiros termos em uma única O(nd). Agora, note que logn é muito menor do que d, por exemplo, se temos 10 milhões de fotos com 256 (d) pixels cada um, logn seria 7, muito menor do que d. Isso significa que podemos transformar o O(nlogn) em outro O(nd). Por conseguinte, a complexidade computacional desse algoritmo é O(nd), isto é, linear, tanto o seu número total de imagens na nossa base de dados e o número de pixels por imagem.
 Fig 3: k-vizinhos mais próximos para algumas fotos. Cada linha representa as principais 9 imagens mais similares à primeira imagem na linha
Fig 3: k-vizinhos mais próximos para algumas fotos. Cada linha representa as principais 9 imagens mais similares à primeira imagem na linha
3 – Podemos fazer melhor?
Se fizermos a análise de complexidade computacional, é natural que nos perguntemos se podemos melhorar. Então, vamos tentar.
Uma ideia a ser considerada é usar uma pilha para manter o controle dos itens k mais semelhantes. A pilha nunca seria maior do que k, assim cada inserção envolve computações de similaridade O(logK) (O(d)), de modo que uma inserção é O(dlogk). Uma vez que haverá n inserções, no total, obtemos O(ndlogk), o que não é uma melhoria.
Nós também podemos tentar explorar o fato de que não precisamos classificar os elementos n, apenas obter o k do topo. O algoritmo seria exatamente o mesmo, mas o passo 3 seria substituído pela aplicação de quick-select em vez de triagem. Isso iria alterar o termo O(nlogn) para o termo O(n), que dá O(nd)+O(n), que é O(nd) – de novo, não uma melhoria.
A última ideia que vamos considerar é usar Space Partitioning Tree (SPT). Um SPT é uma estrutura de dados que nos permite encontrar o objeto mais próximo de outro objeto no tempo logarítmico. A priori, essa parece ser a solução certa, mas há um problema: SPT pode operar apenas sob certas funções de distância, especificamente distâncias métricas.
SPTs trabalham com distâncias, não com similaridades. Mas há uma relação muito estreita entre a semelhança e a distância. No contexto do k-NN, para cada função de similaridade existe uma função de distância tal que procurar pelos itens k mais semelhantes é equivalente a procurar os itens k mais próximos utilizando a função de distância. Apenas multiplicando a semelhança por -1 dá essa distância. Portanto, agora temos uma distância cosseno que poderíamos usar em um SPT, mas infelizmente essa distância cosseno não é uma distância métrica.
Uma distância métrica é a distância que cumpre as seguintes condições:
- distance(x,y)≥0
- distance(x,y)=0⟺x=y
- distance(x,y)=distance(y,x)
- distance(x,z)≤distance(x,y)+distance(y,z)
A distância cosseno viola claramente a primeira condição, mas isso é fácil de resolver apenas adicionando 1. A segunda e a terceira condições são cumpridas. Finalmente, a quarta condição é violada e, desta vez, não podemos corrigir isso. Aqui está um exemplo de 3 vetores que violam a quarta condição:
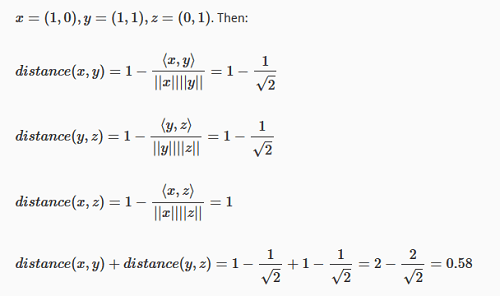
E depois:
distance(x,z)≰distance(x,y)+distance(y,z)
o que prova que a condição 4 não é cumprida.
Nas seções seguintes, vamos mostrar um truque para superar essa limitação.
4 – Matemática
Vamos introduzir algumas propriedades dos vetores que vamos explorar mais tarde.
A distância do cosseno é invariante sob normalização
Em primeiro lugar, vamos fazer algumas definições:
- Norma de um vetor X: denotado por ∥X∥ e calculado como √ΣdiX2i. Isso é exatamente o comprimento geométrico do vetor.
- Normalização do vetor: denotado por ^X e computado como X/∥X∥ que está apenas dividindo cada componente do vetor X pela norma de X.
A consequência dessas duas definições é a seguinte:
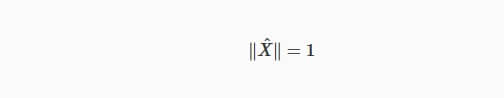
Que diz que a norma de um vetor normalizado é sempre 1. Essa propriedade é bastante óbvia, mas aqui está uma prova:
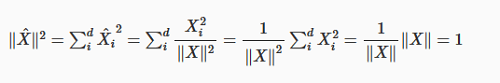
E como ∥^X∥ deve ser positivo, concluímos que ∥^X∥=1.
Outra consequência é a seguinte:
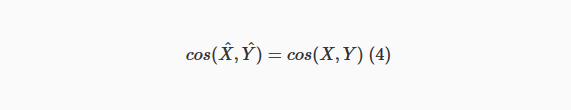
Em outras palavras, isso significa que o ângulo entre os dois vetores não muda quando os vetores são normalizados. A normalização apenas altera o comprimento (a norma do vetor), não a sua direção e, portanto, o ângulo é sempre mantido. Mais uma vez, aqui está a prova:
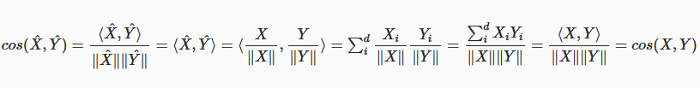
Agora, uma vez que cos (^X,^Y)=cos(X,Y), então também 1-cos(^X,^Y)=1-cos(X,Y), o que significa que a distância cosseno entre X e Y é exatamente a mesma que a distância cosseno entre a versão normalizada de X e Y.
De Euclidiana para cosseno
A segunda propriedade que precisamos para esse truque é a seguinte:
Se X e Y são vetores com a norma 1 (vetores unitários), então:
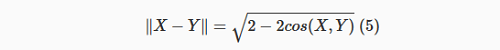
Isso indica que se X e Y são vetores unitários, então existe uma relação exata entre a distância euclidiana de X para Y e o ângulo entre eles.
A prova:
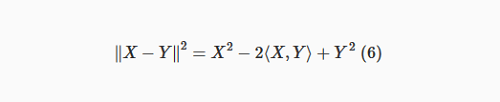
Como X é um vetor de unidade, então, X2=⟨X, X⟩=ΣdiXiXi=∥X∥2=1, do mesmo modo, Y2=1, então temos:
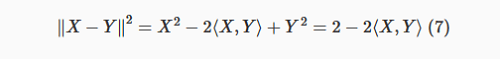
Como X e Y são vetores unitários, dividir por sua norma é dividir por um:
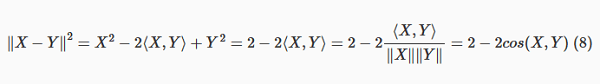
Ranking de cosseno é equivalente ao ranking Euclidiano
Ao olhar para a equação 5, já podemos ver que se 1-cos(X,Y) é maior, então ∥X-Y∥ deve ser maior. Isso significa que se Y fica longe de X no espaço euclidiano, ele o faz também no espaço do cosseno, desde que ambos X e Y sejam vetores unitários. Isso nos permite estabelecer o seguinte:
Considere três vetores arbitrários d-dimensionais X, A e B (que não precisam ser vetores unitários). Em seguida, faça o seguinte:
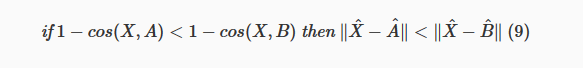
Essa equação diz que se a distância entre o cosseno X e A é menor que a distância entre o cosseno X e B, então a distância euclidiana entre X e A é também menor do que a distância euclidiana entre X e B. Em outras palavras, se A é mais perto de X do que B no espaço de cosseno, é também mais próximo no espaço euclidiano.
A prova: partimos da expressão do lado esquerdo e aplicamos operações para chegar à expressão do lado direito.
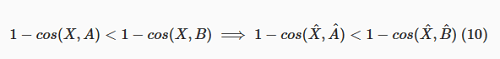
cosseno é invariante sob a normalização (ver equação 4).
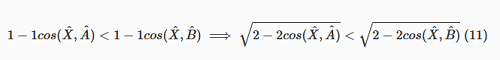
dobrando e pegando a raiz quadrada mantém a desigualdade.
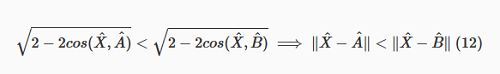
vetores normalizados são vetores unitários e equação 5.
Essa é toda a matemática necessária para aplicar o truque. Na próxima parte, vamos ver do ele trata, além de experimentos e resultados.
***
Lucas Bernardi faz parte do time de colunistas internacionais do iMasters. O artigo foi publicado originalmente em Booking.com. A tradução do artigo é feita pela redação iMasters, com autorização do autor, e você pode acompanhar o artigo em inglês no link: http://blog.booking.com/k-nearest-neighbours-from-slow-to-fast-thanks-to-math.html. Se tiver alguma pergunta, entre em contato pelo Twitter (@planetbooking).

De 0 a 10, o quanto você recomendaria este artigo para um amigo?