

Eliminar duplicações de registros é um desafio comum, e existem alguns diferentes métodos para fazer isso, então vamos conhecer mais um, o uso do %%physloc%%.
O %%physloc%% nos permite obter a localização física de um registro dentro da estrutura de arquivos/páginas. Claro que cada registro possui uma localização física diferente, portanto podemos utilizar o %%physloc%% para eliminar as duplicações.
Vamos começar com um pequeno cenário de tabela com dados duplicados:
create table testeDuplicacao
( nome varchar(50) )
go
insert into testeDuplicacao values ('joao'),('joao')
insert into testeDuplicacao values ('jose'),('jose')
insert into testeDuplicacao values ('pedro')
go
Obter o %%physloc%% é bem simples:
select *,%%physloc%% from testeDuplicacao
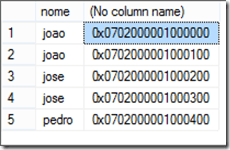
O valor mostrado no physloc não tem um significado diretamente, não nesse formato. Se desejarmos por algum motivo ver seu significado, devemos formatá-lo. Veja como fica:
SELECT *,
sys.fn_PhysLocFormatter(%%physloc%%)
AS [Physloc]
from testeduplicacao
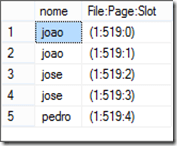
O formato significa File:Page:Slot, indicando assim a localização do registro. Porém essa formatação é uma curiosidade, não é necessário utilizá-la para resolver o problema da duplicação.
Observando visualmente o resultado, podemos deletar os registros duplicados copiando manualmente o physloc para instruções delete. Veja como fica um exemplo:
delete testeduplicacao where %%physloc%% = 0x0702000001000100
Porém o ideal é montarmos uma query que, utilizando o physloc, nos permita eliminar todos os registros duplicados. Podemos eliminar todos os physloc de uma duplicação menos um que escolheremos – pode ser o maior, por exemplo. Então selecionamos todos, menos esse, para a eliminação.
delete testeduplicacao where %%physloc%% in
(select fisloc from
(select nome, %%physloc%% as fisloc,
max(%%physloc%%) over (partition by nome) as maiorfisloc
from testeduplicacao) a
where fisloc<>maiorfisloc)
Com isso, eliminamos as duplicações utilizando o %%physloc%%.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?