

Tem inúmeras coisas no mundo de TI que nos são vendidas como se fossem mais fáceis que roubar doce de criança… e que no final sempre viram um pesadelo. Dá pra fazer uma lista enorme de itens: a criação de backups de bancos, a codificação usando as linguagens X, Y ou Z, a configuração de regras de segurança de firewall etc.
Um dos meus itens preferidos nessa lista das “coisas-fáceis-mas-nem-tanto” é a importação de dados em formato texto. Quem nunca trabalhou com alguma transferência de dados séria vai lhe dizer “não se preocupe, porque isso eu faço rapidinho”.
Pode até ser que essa pessoa tenha sorte suficiente para que nada de anormal aconteça nessa movimentação de dados. Porque a sorte é mesmo fator determinante para o tempo que você vai gastar para executar o processo.
Existem inúmeras ferramentas e técnicas para tratar de importação de arquivos texto. Eu conheço algumas bem interessantes, mas muitas vezes essas ferramentas me deixaram na mão e fui obrigado a improvisar.
É aí que entram as tais “técnicas” que mencionei. A seguir, comentarei algumas das técnicas que auxiliam na movimentação de dados entre ambientes diferentes.
Tipos de arquivo texto
Quando se fala de importação de dados em formato texto, temos basicamente dois mundos diferentes: as arquivos de largura fixa ou arquivos com separadores de campos.
1. Arquivos de largura fixa, muito usados no ambiente de mainframe
Os arquivos de largura fixa são interessantes porque neles pode-se incluir qualquer tipo de caractere. As únicas coisas que importam são a posição inicial e a posição final do campo, que têm que ser idênticas para todas as linhas do arquivo.
Na figura a seguir, vemos um exemplo desses arquivos. As linhas vermelhas representam as posições em que terminam um campo e começam o campo seguinte.
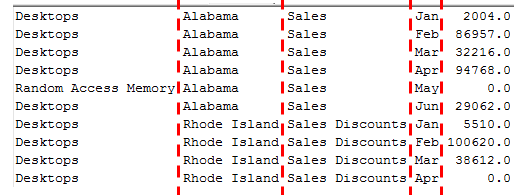
O problema dos arquivos de largura fixa é que eles não funcionam bem com campos muito longos. Imagine que o arquivo tenha um campo de comentário que pode ocupar entre 0 e 500 caracteres. Não faz diferença quantos caracteres são de fato usados. O campo é tratado como uma coluna, e é necessário reservar 500 posições para esta coluna.
Evidente que isso causa um desperdício enorme de recursos, aumentando em muito o tamanho final do arquivo.
2. Arquivos com separadores de campos
Os arquivos com separadores de campos são bem mais eficientes do ponto de vista do aproveitamento de espaço, porque basta incluir um separador no final do valor correspondente a cada campo. Assim, não há desperdício de espaço, como mostra a figura a seguir.

O separador de campo tem que ser um caractere que não é usado em nenhuma linha do arquivo. Normalmente, o caractere usado como separador de campo é a vírgula (“,”). Mas é preciso tomar cuidado para evitar dois tipos de problema:
- se você estiver no Brasil e seus dados incluírem campos numéricos, provavelmente o arquivo usará a vírgula como símbolo decimal. Se o separador de campos também for a vírgula, importação irá falhar.
- se campos de texto do arquivo incluírem a vírgula, de novo você terá problemas. Sua ferramenta de importação não saberá diferenciar se o caractere encontrado é parte do texto ou se é o próprio separador de campos.
Naturalmente, esses dois problemas podem acontecer com outros caracteres que você possa escolher como separador de campos. Portanto, é necessário ter muita atenção nessa questão.
Solucionando o caso do separador de decimais
O separador de decimais de um número é definido nas configurações regionais do Windows. Veja as telas de configuração “Região e Idioma” e “Configurações Adicionais”.
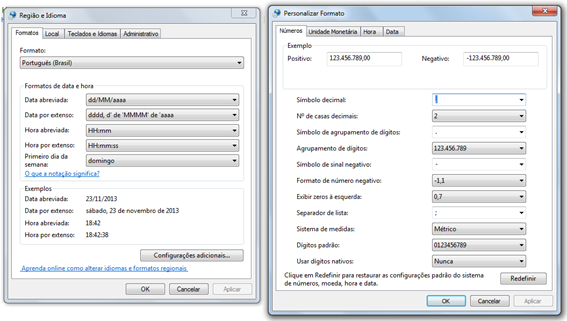
Essas telas lhe oferecem dois caminhos: você pode alterar o caractere de decimal ou o separador de lista padrão do Windows. Em qualquer dos casos, o ideal é corrigir essas configurações antes de gerar os arquivos.
Solucionando o caso dos textos que contenham o separador de campos
Campos texto geralmente são livres, ou seja, o usuário pode digitar qualquer caractere reconhecido no COLLATION do banco de dados. Portanto, o usuário tem total liberdade e pode muito bem digitar um caractere igual ao que você escolheu como separador de campos.
Por causa disso, é recomendável que se use um segundo caractere especial que chamamos de delimitador de texto. Ou seja, marcamos o início do campo texto com esse novo caractere (que obviamente tem que ser diferente do separador de campos) e repetimos o mesmo caractere no final do campo. Desse jeito, todos os caracteres que estiverem entre essas duas marcas farão parte de um único campo texto.
Geralmente, usamos as aspas duplas como delimitador de campos. De novo, é preciso muita atenção na escolha do delimitador de texto, para evitar o problema que o caractere escolhido faça parte do conteúdo de algum campo texto.
Surpresas no caminho
Tudo parece resolvido, mas ainda não cobrimos todas as situações de erro.
Nos arquivos com separadores de campos, basta escolher um caractere para separar campos, outro caractere para delimitar textos, mais um para símbolo decimal e tomarmos o cuidado de não usarmos esses caracteres especiais fora de posição dentro do arquivo.
Nos arquivos de largura fixa, todos os caracteres são permitidos dentro do texto, porque não existem caracteres especiais. Só importa a posição de início e fim de cada campo.
Eis que surge um grande vilão, escondido no que parecia ser o mundo perfeito.
Como já disse, usuário pode digitar qualquer caractere num campo texto, inclusive um caractere para identificar uma nova linha (também chamado de line feed, carriage return ou CRLF).
E aí, meu caro, você tem um problemão nas mãos. Simplesmente porque a gente nunca para pensar, mas nós usamos esse caractere em todo arquivo texto, seja ele do tipo que for. Esse caractere é separador de linhas e indica o final do registro.
Enquanto esse caractere CRLF estiver no meio dos campos texto, não importa se o seu arquivo é de largura fixa ou se usa separador de campos e delimitador de texto. Quando ele for encontrado, a ferramenta de importação entenderá que ali começa um novo registro. E então começarão seus problemas.
Como lidar com o CRLF nos campos de texto
Eu confesso que nunca encontrei uma maneira eficaz de distinguir os vários tipos de separadores de linha. Às se usa o LF (line feed), em outras se usa o CR (carriage return) ou ainda a combinação dos dois: CRLF.
Sendo assim, eu costumo usar duas abordagens. Sempre que possível, eu substituo o separador de linhas dos campos texto por algum outro caractere qualquer para marcar a posição e permitir que eu faça a importação. Depois disso, se necessário, eu atualizo a tabela importada substituindo o caractere de marcação por um caractere UNICODE adequado.
Em alguns casos, eu prefiro trocar o caractere de terminação de registro, escolhendo um caractere que não foi usado no texto. Isso vai deixar o arquivo texto com uma cara muito estranha, porque não haverá “linhas” correspondentes aos registros, mas o que importa é que funciona.
Identificando uma lógica para o procedimento
Geralmente a gente descobre o problema com caracteres CRLF na fase final do processo importação de dados, quando já foi gerado e movido para a máquina de destino um arquivo texto enorme, muitas vezes com milhões de linhas.
Quando isso acontece, é mais fácil editar o próprio arquivo texto do que voltar para máquina de origem e exportar novamente os dados, corrigindo os caracteres. Tudo depende de você encontrar uma lógica nos dados que lhe permita substituir todos os caracteres de uma só vez. Se você conseguir definir essa lógica que atenda a uns 90% dos registros, já é meio caminho andado. (O que não atender à regra deverá ser tratado manualmente… não tem jeito).
Por exemplo: imagine que as linhas do seu arquivo sempre começam com um campo texto, que usa o separador aspas duplas. É muito pouco provável que os campos de texto que incluem o caractere CRLF tenham exatamente os caracteres CRLF e aspas duplas em sequência.
Neste exemplo, você conseguirá resolver o problema em dois passos:
- substituindo todos os caracteres CRLF por algum caractere que não exista no arquivo (por exemplo: @); isso elimina os caracteres errados e ainda deixa um marcador na posição onde de fato deve existir o caractere CRLF.
- substituindo todas as ocorrências da cadeia de caracteres @“ (arroba seguido de aspas duplas) pelo caractere CRLF; isso restaura as marcas de nova linha nas posições devidas.
Como substituir caracteres CRLF dentro de arquivos texto
Definido o procedimento, resta executá-lo. Muita gente se pergunta que ferramentas usar para essa ação, mas a solução é simples.
Seja em ambiente Windows ou Unix, o caractere CRLF normalmente é identificado pelo código [\r\n]. Apenas precisamos escolher a ferramenta a se usar.
Se você tiver a oportunidade de tratar esse arquivo numa máquina Unix, eu recomendo que o faça. Editar arquivos grandes no “vi” do Unix é absurdamente mais rápido do que qualquer coisa que você consiga fazer em editores de texto do Windows. A diferença costuma ser da ordem de 100 vezes mais rápido quando se fala de arquivos grandes.
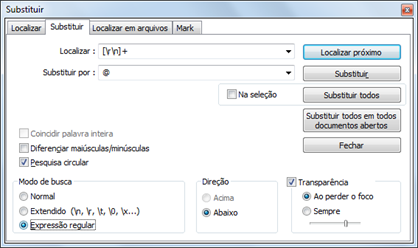
No “vi”, basta executar a seguinte instrução para substituir todos os caracteres CRLF pelo caractere @:
(ambiente UNIX, ferramenta vi) :%s/[\r\n]/@/g
Se você for executar a operação em Windows, sugiro usar o freeware Notepad++. Você não terá dificuldades técnicas para abrir arquivos texto de qualquer tamanho e executar as operações desejadas. A limitação é que os processos serão bem lentos (e, até onde eu sei, isso acontecerá com qualquer editor de texto do Windows).
O principal cuidado é ativar a pesquisa com uso de expressões regulares (REGEX).
Conclusão
No frigir dos ovos, existem duas diretrizes para se evitar problemas com arquivos texto:
- antes de gerar o arquivo texto, verifique se existem campos texto que usam o caracter de separador de linha.
- se você for usar arquivos com separadores de campos, use delimitadores de texto e escolha com muito cuidado os caracteres para:
- separador de campos
- delimitador de texto
- símbolo decimal
Esses pequenos truques já salvaram meu dia em muitas ocasiões. Por isso, da próxima vez que for importar arquivos texto, lembre-se de tratar essa tarefa com muito respeito… e de ter à mão alguns truques para te tirar de possíveis enrascadas.
Até a próxima!

De 0 a 10, o quanto você recomendaria este artigo para um amigo?