

Com o aumento do número de linhas presentes nas tabelas de uma base de dados, percebe-se o aumento da utilização de recursos computacionais para realizar consultas mais complexas, principalmente aquelas que envolvem junções entre duas ou mais tabelas.
É nítido que, mesmo em um cenário ideal, com todas as tabelas normalizadas e perfeitamente indexadas, as junções tendem a ser o mais frequente problema de desempenho nas consultas para geração de relatórios ou análises mais complexas entre os dados dispersos por várias tabelas. Este cenário é ainda mais crítico em aplicações web que disponibilizam dados em tempo real, como a maioria dos sites sociais, onde a informação deve estar atualizada sempre que o usuário executa uma ação ou recarrega uma página.
Evitar junções que sejam custosas para as consultas realizadas mais frequentemente é a proposta da implementação da redundância controlada de dados em um banco de dados relacional. Em tabelas que concentram uma ou mais chaves estrangeiras, criam-se campos redundantes, isto é, campos duplicados e idênticos aos campos de mesmo conteúdo da tabela que é referenciada por cada chave.
Por exemplo, em um cenário em que uma tabela possui cinco chaves estrangeiras, ao realizar uma consulta em que são necessários dados de todas as seis tabelas – a tabela principal e as outras cinco que são referenciadas pelas chaves estrangeiras – serão utilizadas cinco junções. Caso a tabela principal tenha recebido campos redundantes para cada uma das chaves estrangeiras, a consulta não requerirá nenhuma junção, visto que todas as informações necessárias estarão reunidas na mesma linha. Assim sendo, ao invés de realizarmos uma consulta com cinco junções, estaremos realizando apenas uma consulta simples.
Todavia, nem tudo é vantagem. Ao adotar a redundância controlada, troca-se a agilidade na escrita pela agilidade na leitura. Isto é, a responsabilidade de cultivar este ambiente facilitado para a leitura será custeado pelo maior esforço para a realização de operações de escrita – inserções, atualizações e exclusões. Será destas operações a responsabilidade de manter em dia, sempre atualizados, todos os campos redundantes presentes nas tabelas que foram otimizadas para leitura sem junções. Tal característica resulta nas seguintes implicações:
- A redundância controlada é recomendada para bases de dados em que há um grande número de leituras, porém, um baixo número de escritas. Por exemplo, uma tabela que armazena registros de artigos publicados em um blog se beneficiará, pois cada artigo foi escrito uma vez e raramente será editado, contudo, estará constantemente sendo lido. Por outro lado, uma tabela que armazena grande quantidade de informações transacionais, com grande volume de escrita e baixa quantidade de leituras, será prejudicada, uma vez que, a cada escrita, despenderá recursos atualizando dados redundantes cuja utilidade será pequena.
- A consistência das informações redundantes será de responsabilidade de quem atualiza a tabela que contém os campos originais. Assim, ao atualizar um dado em um campo que está replicado em outra tabela, a atualização deverá ser atômica, a fim de manter a consistência da base de dados. Entretanto, as chaves estrangeiras continuam mantendo a integridade referencial com suas respectivas chaves primárias.
Ao adicionar campos redundantes a uma tabela, realiza-se algo conhecido como “desnormalização”. Isto não significa abrir mão de todas as formas normais, mas sim, de maneira consciente e planejada, otimizar as tabelas para um propósito específico. Geralmente, ao implementar a redundância controlada em uma base de dados normalizada, regride-se a segunda forma normal, que continua sendo atendida.
Quanto maior a adesão às formas normais, maior a qualidade dos dados e, por consequência, maior a segurança de que a consistência será garantida pelo sistema gerenciador de banco de dados. O sistema gerenciador de banco de dados é capaz de garantir a integridade referencial entre chave estrangeira e chave primária, entretanto, não oferece nenhuma garantia de consistência para valores duplicados nos campos redundantes. Assim, é inegável que, ao implementar a redundância controlada, aumentará o trabalho de codificação por parte da aplicação que manipula os dados para que a consistência possa ser garantida.
Reitera-se, então, a importância da análise a fim de constatar se a redundância controlada é, de fato, a melhor opção a ser adotada. Igualmente, é importante lembrar que cada sistema gerenciador de banco de dados oferece recursos próprios que, em alguns casos, podem facilitar a leitura dos dados e poupar junções. É o caso das views materializadas e suas variações, disponíveis no PostgreSQL, SQL Server e Oracle, que possibilitam manter um modelo lógico totalmente normalizado e, ainda assim, contar com consultas bastante otimizadas.
Reconhecidamente, o MySQL é um sistema gerenciador bastante espartano e, assim, não inclui este tipo de recurso. Logo, nas próximas seções, partiremos para a implementação da redundância controlada a partir de um modelo lógico normalizado.
O modelo normalizado
O diagrama abaixo apresenta um modelo normalizado, com três tabelas que possuem relações entre si:
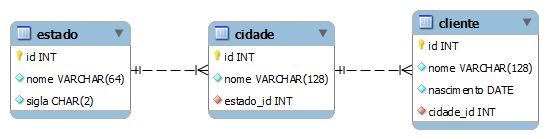
Pode-se concluir que este modelo está normalizado, pois atende plenamente aos requisitos da terceira forma normal:
- Não possui atributos multivalorados ou tabelas aninhadas. Todos os atributos são atômicos, fazendo-o atender à primeira forma normal;
- Como todas as chaves primárias são simples, logo, todos os atributos não-chave dependem da chave completa e não apenas de parte dela, cumprindo a segunda forma normal;
- Todos os atributos não-chave dependem exclusivamente da chave primária. Não há qualquer atributo que dependa de outro atributo não-chave, atendendo à terceira forma normal.
A representação normalizada assegura a qualidade dos dados e minimiza os riscos de perda de integridade, uma vez que a maioria dos sistemas gerenciadores de bancos de dados relacionais implementa o controle da integridade referencial. Isso garante que todo atributo chave estrangeira terá um correspondente na tabela que é referenciada, evitando registros órfãos.
Supondo que este conjunto de dados deverá gerar um relatório, atualizado a cada segundo, com uma listagem completa de todos os clientes e suas respectivas cidades, incluindo também a sigla do estado a qual pertence, é notável que, inevitavelmente, será necessário recorrer a junções entre três tabelas para que o resultado desejado seja alcançado.
Na forma simplificada:
select cliente.nome as cliente, cidade.nome as cidade, estado.sigla as estado from cliente, cidade, estado where cliente.cidade_id = cidade.id and cidade.estado_id = estado.id
Ou na forma com junção explícita:
select cliente.nome as cliente, cidade.nome as cidade, estado.sigla as estado from cliente inner join cidade on cliente.cidade_id = cidade.id inner join estado on cidade.estado_id = estado.id
Ambas as implementações apresentam o mesmo resultado:
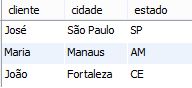
Fica evidente a utilização de junções para que o relatório possa ser gerado. Independentemente da ocorrência de alterações nos dados, a cada segundo, o relatório realizará o mesmo processo de junção de três tabelas, a fim de reunir e associar todos os dados.
Conforme a tabela “cliente” se expande em número total de registros, existe a tendência de um aumento considerável no volume de recursos computacionais exigidos para o processamento da consulta. Quanto maior o número de registros, e maior o número de junções, maior o esforço computacional para realizar as associações entre os registros de todas as tabelas.
Assim, considerando que as tabelas “estado” e “cidade” sofrem operações de escrita com uma frequência extremamente baixa e a tabela “cliente” é atualizada alguma centena de vezes ao dia, enquanto recebe algumas centenas de milhares de consultas com junções, é notório que, para este cenário, a taxa de operações de leitura por operação de escrita (read/write ratio) é substancialmente elevada, o que abre espaço para implementações alternativas, que buscam transferir o ônus das junções para o momento em que se realizam operações de escrita.
Trabalhando com a redundância controlada
A figura 3 apresenta o mesmo modelo da figura 1, no entanto, com a adição de atributos redundantes nas entidades “cidade” e “cliente”.
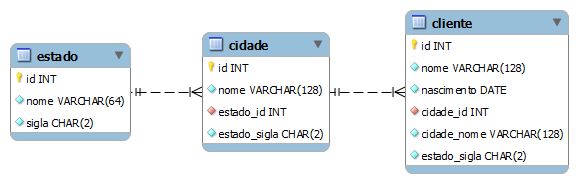
Enquanto a entidade “estado” permaneceu com seus atributos inalterados, quando comparada ao modelo normalizado, no modelo com atributos redundantes, a tabela “cidade” recebeu o atributo redundante “estado_sigla”, que é uma cópia de “sigla” presente em “estado”. Já a entidade “cliente” recebeu dois atributos redundantes, “cidade_nome”, proveniente de “cidade”, e “estado_sigla”, proveniente de “estado”.
Analisando este modelo, constata-se que a terceira forma normal foi intencionalmente abandonada. Os atributos redundantes em “cidade” e “cliente” não são dependentes da chave primária, mas sim de outro atributo, que é chave estrangeira. Na entidade “cidade”, o atributo redundante “estado_sigla” depende da chave estrangeira “estado_id”, e na entidade “cliente”, “cidade_nome” e “estado_sigla” dependem da chave estrangeira “cidade_id”.
Com o intuito de garantir a integridade dos dados, é fundamental que as operações de escrita garantam a correta duplicação dos dados que estão armazenados com redundância. Neste sentido, diversas abordagens podem ser adotadas:
- Atualização pela linguagem de programação: o aplicativo que manipula os dados será responsável por manter a integridade dos dados redundantes. Por meio da linguagem de programação utilizada no aplicativo, desenvolvem-se rotinas de atualização combinada dos dados em duas ou mais tabelas em que existem atributos redundantes.
- Atualização por meio de triggers: triggers possibilitam atualização de uma maneira totalmente transparente para o usuário que acessa a base de dados. De acordo com a natureza da operação de escrita realizada em uma tabela, automaticamente, uma rotina de atualização de todos os dados redundantes é iniciada.
- Atualização por meio de stored procedures: este é o modelo mais restritivo entre os três aqui expostos, já que todas as permissões de inserção e atualização nas tabelas que possuem dados em redundância são canceladas. A única via de acesso para atualização dos dados destas tabelas é por meio de uma stored procedure.
Entre as três abordagens levantadas, o modelo de atualização pela linguagem de programação é tido como o mais inseguro, uma vez que o administrador do banco de dados não possui nenhuma garantia de como os dados redundantes serão tratados, sobretudo quando uma base de dados é compartilhada entre vários aplicativos diferentes. Neste caso, o ideal é que haja uma camada ou serviço específico para o acesso a dados, que possa ser compartilhado entre todos os aplicativos.
O modelo de atualização por triggers possui uma implementação simplificada e garante que todas as operações de atualização sejam realizadas de uma forma bastante natural. Inserções e atualizações podem ser feitas livremente nas tabelas, enquanto triggers fazem todo o trabalho de controle das redundâncias de uma forma transparente. Entretanto, alguns administradores de bancos de dados podem preferir evitar trabalhar com triggers.
Já a atualização por stored procedures garante total segurança no controle dos dados redundantes, uma vez que todos os privilégios de escrita são retirados dos usuários, a fim de que o único meio de inserção e atualização de linhas em uma tabela seja uma stored procedure. Apesar de muito segura, a implementação desta abordagem exige um considerável volume de codificação em linguagem SQL e pode dificultar o relacionamento entre o banco de dados e alguma ferramenta de mapeamento objeto-relacional utilizada pelo aplicativo.
O exemplo a seguir demonstra uma proposta de implementação simplificada do controle de redundâncias por meio de stored procedures no MySQL.
Implementação no MySQL usando stored procedures
Para cada tabela envolvida com dados redundantes, criar-se-á uma stored procedure, cuja responsabilidade será realizar as operações de escrita na própria tabela e as devidas atualizações de colunas redundantes, tanto na mesma tabela como em outras que possuam atributos redundantes copiados desta tabela.
Por exemplo, ao atualizar uma linha na tabela “estado”, a stored procedure “salvar_estado” deverá replicar esta atualização para as tabelas “cidade”, em que há a coluna “estado_sigla”, e para a tabela “cliente”, em que há outra coluna homônima. Cabe a cada stored procedure realizar as atualizações devidas em campos externos que armazenam informações desta tabela de forma redundante.
delimiter $ create procedure salvar_estado(in _id int, in _nome varchar(64), in _sigla char(2)) begin if _id is null then insert into estado(nome, sigla) values(_nome, _sigla); else start transaction; update estado e set e.nome = _nome, e.sigla = _sigla where e.id = _id; update cidade c set c.estado_sigla = _sigla where c.estado_id = _id; update cliente c set c.estado_sigla = _sigla where c.cidade_id in (select c.id from cidade c where c.estado_id = _id); commit; end if; end $ delimiter ;
Assim como uma tabela que possui colunas redundantes em outras tabelas deve atualizá-las quando é alvo de uma operação de atualização, toda tabela que possui colunas redundantes também deverá atualizá-las sempre que uma nova linha for adicionada ou uma operação de atualização alterar o valor da coluna que é chave estrangeira, cujo campo redundante é dependente. Este comportamento pode ser observado na implementação do procedimento “salvar_cidade”, que corresponde à tabela “cidade”, que possui uma de suas colunas em redundância na tabela “cliente” e também mantém uma cópia da coluna “estado_sigla”, que pertence à tabela “estado”.
delimiter $ create procedure salvar_cidade(in _id int, in _nome varchar(128), in _estado_id int) begin declare _sigla char(2); select sigla into _sigla from estado where id = _estado_id; if _id is null then insert into cidade(nome, estado_id, estado_sigla) values (_nome, _estado_id, _sigla); else start transaction; update cidade c set c.nome = _nome, c.estado_id = _estado_id, c.estado_sigla = _sigla where c.id = _id; update cliente c set c.cidade_nome = _nome, c.estado_sigla = _sigla where c.cidade_id = _id; commit; end if; end$ delimiter ;
Por fim, a stored procedure salvar_cliente realiza a mesma operação na tabela “cliente”:
delimiter $ create procedure salvar_cliente(in _id int, in _nome varchar(128), in _nascimento date, in _cidade_id int) begin declare _cidade_nome varchar(128); declare _estado_sigla char(2); start transaction; select c.nome, c.estado_sigla into _cidade_nome, _estado_sigla from cidade c where c.id = _cidade_id; if _id is null then insert into cliente(nome, nascimento, cidade_id, cidade_nome, estado_sigla) values(_nome, _nascimento, _cidade_id, _cidade_nome, _estado_sigla); else update cliente c set c.nome = _nome, c.nascimento = _nascimento, c.cidade_id = _cidade_id, c.cidade_nome = _cidade_nome, c.estado_sigla = _estado_sigla where c.id = _id; end if; end$ delimiter ;
Para inserir ou alterar registros nas tabelas, basta efetuar chamadas à respectiva stored procedure. Nesta implementação, o parâmetro “_id” determinará se a operação é uma inserção ou atualização. Quando nulo, caracteriza-se um pedido de inserção. Quando definido, há um pedido de alteração do registro identificado pelo mesmo código:
call salvar_cliente(null, 'José', '1970-02-12', 2); call salvar_cliente(null, 'Maria', '1982-12-12', 5); call salvar_cliente(null, 'João', '1947-08-08', 4); call salvar_cliente(1, 'Antônio', '1970-02-12', 2);
Para inserir ou alterar registros nas tabelas, basta efetuar chamadas à respectiva stored procedure. Nesta implementação, o parâmetro “_id” determinará se a operação é uma inserção ou atualização. Quando nulo, caracteriza-se um pedido de inserção. Quando definido, há um pedido de alteração do registro identificado pelo mesmo código:
call salvar_cliente(null, 'José', '1970-02-12', 2); call salvar_cliente(null, 'Maria', '1982-12-12', 5); call salvar_cliente(null, 'João', '1947-08-08', 4); call salvar_cliente(1, 'Antônio', '1970-02-12', 2);
Ao término da implementação da redundância controlada, verifica-se que, agora, a mesma consulta pode ser realizada sem a utilização de junções. A consulta para gerar o mesmo relatório, anteriormente apresentado (representado pela figura 2) foi otimizada e é executada com uma simples busca por chave primária, em apenas uma tabela:
select nome as cliente, cidade_nome as cidade, estado_sigla as estado from cliente
Considerações finais
A redundância controlada é uma técnica cuja utilização vem ganhando espaço em bancos de dados relacionais, principalmente em bases de dados que atendem sistemas online em que há tendência de grande volume de leituras e baixo número de operações de escrita.
É importante frisar que erros nesta implementação podem resultar em grandes riscos à integridade dos dados e ao próprio desempenho e disponibilidade do serviço de banco de dados. Por outro lado, quando bem projetada e implementada, a redundância controlada é capaz de trazer benefícios consideráveis, poupando o servidor de banco de dados da carga imposta pelas junções nas consultas realizadas mais frequentemente.
Em bancos de dados relacionais com maior leque de recursos, deve-se também observar a possibilidade de utilização de views materializadas e recursos de cache de consultas, cuja implementação é menos onerosa e arriscada do que recorrer a técnicas que envolvem a desnormalização, como a redundância controlada.
Ater-se às formas normais é a melhor forma de garantir a qualidade e a integridade dos dados. Além disso, violar uma ou mais formas normais no projeto do banco de dados implicará uma maior quantidade de trabalho de codificação e testes, afinal, tanto os sistemas gerenciadores de bancos de dados relacionais quanto as principais ferramentas de mapeamento objeto-relacional foram desenvolvidos para trabalhar em modelos normalizados. Ao recorrer à desnormalização, abre-se mão de certa produtividade durante a codificação, em prol de um melhor desempenho de leitura das informações armazenadas durante o uso do aplicativo.
Cabe lembrar, ainda, que existem outras abordagens para armazenamento de dados que fogem do padrão relacional e podem ser bastante otimizadas para sistemas com leitura intensiva dos dados. Este tipo de banco de dados pode simplificar a recuperação de informações ao agregar vários objetos dentro de um mesmo documento.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?