

Um importante passo no aprendizado de máquina é criar ou encontrar dados adequados para o treinamento e teste do algoritmo. Trabalhar com um bom conjunto de dados ajudará você a evitar ou detectar erros em seu algoritmo e a melhorar os resultados de sua aplicação. Como criar o seu próprio conjunto de dados é uma tarefa muito demorada na maioria dos casos, neste artigo, vou apresentá-lo a alguns conjuntos úteis para a classificação de texto e problemas de classificação de imagens.
Classificação de textos
- Spam – Não Spam;
- Análise de sentimento;
- Classificação pelo assunto.
Classificação de imagens
- Números e letras;
- Faces;
- Animais;
- Vários objetos.
Classificação de texto
Nas seções seguintes, você encontrará conjuntos de dados que podem ser usados para tarefas de classificação de texto comum, tais como a detecção de mensagens de spam, análise de sentimento e a classificação por assunto de um documento.
Spam e Não Spam
A tarefa de filtragem de spam é muito comum na classificação de textos. Portanto, uma série de conjuntos de dados podem ser encontradas para esse objetivo.
SMS Spam Corpus
O SMS Spam Corpus consiste em mensagens de texto que pertencem a uma de duas classes. Cada elemento é marcado como spam ou ham. Pode-se baixar a versão grande do conjunto (1002 ham, 322 spam) ou a pequena (1002 spam, 82 spam).
Enron Dataset
Se, em vez disso, o seu interesse for em filtragem de spam em e-mails, você pode estar interessado no conjunto de dados Enron, que fornece uma coleção de milhares de e-mails, classificados como spam ou ham. Ele pode ser baixado em uma versão crua ou pré-processada.
Outros bancos de dados para a classificação de spam em e-mails que podem ser interessantes para você são SpamAssassin public mail corpus, TREC Public Spam Corpus ou Spambase Data Set.
Análise de sentimento
Outra tarefa que pode ser resolvida por Machine Learning é análise de sentimento de textos. Um exemplo para essa tarefa seria descobrir se um texto afirma uma opinião positiva ou negativa sobre um determinado assunto.
Twitter Sentiment Analysis Training Corpus
No caso de você estar interessado na classificação de sentimentos dos tweets, o Twitter Sentiment Analysis Training Corpus pode ser o conjunto de dados que você está procurando. Ele consiste de mais de 1 milhão de tweets em um arquivo .csv. Cada elemento é rotulado como positivo (1) ou negativo (0).
Movie Review Data
Textos mais complexos podem ser encontrados na Movie Review Data, que fornece uma coleção de 1.000 comentários positivos e 1.000 negativos relacionados a filmes. Os comentários estão disponíveis como arquivos .html não processados e como textos processados. Parte desse conjunto de dados também é uma coleção de frases rotuladas como subjetivas ou objetivas.
Uma lista de conjuntos de dados úteis para a classificação de sentimento foi inserida neste artigo de Kavita Ganesan.
Classificação por assunto
Classificar documentos por seu assunto é um problema complexo. Dependendo dos tipos de documentos com os quais você deseja trabalhar, você precisará de um conjunto de dados apropriado para esse caso exato. Um caso investigado muitas vezes é a classificação de artigos de jornal.
20 Newsgroups
O conjunto de dados do 20 Newsproups contém cerca de 20.000 documentos que são quase uniformemente distribuídos em 20 categorias. Os dados são divididos em um conjunto de treino e teste. Alguns dos grupos de notícias estão intimamente relacionados, enquanto outros não têm nada a ver com o outro. Os grupos no conjunto de dados são os seguintes:
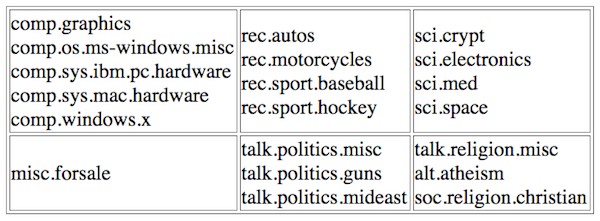
Reuters-21578
Um conjunto de dados que é frequentemente utilizado para avaliar algoritmos de classificação de texto é o Reuters-21578 dataset. Ele é constituído por textos que apareceram no newswire Reuters em 1987 e foi criado em conjunto com a equipe Reuters Ltd. Muitas vezes apenas subconjuntos desse conjunto de dados são usados como os documentos que não estão sendo uniformemente distribuídos ao longo das categorias. Em muitos casos, apenas 10 ou 90 categorias são utilizadas na maioria dos documentos.
Uma coleção muito útil de um único conjunto de dados de texto rotulados é fornecida na página Cachopo de Ana Cardoso Cachopo. Não só você vai encontrar um resumo de dados úteis, mas também versões humanamente legíveis e pré-processadas dos conjuntos de dados, o que pode poupar muito tempo e problemas.
Classificação de imagem
Nas seções seguintes, vamos apresentar alguns conjuntos de dados que podem ser úteis se você quiser usar a aprendizagem de máquina para a classificação de imagem. Os conjuntos de dados listados variam de números simples escritos à mão até imagens de objetos complexos, e podem ser úteis para começar a trabalhar com a classificação de imagem ou testar seu algoritmo.
Números e letras
MNIST
O conjunto de dados MNIST é um comumente utilizado para começar a trabalhar com a classificação de imagens. Ele contém milhares de pequenas imagens binárias rotuladas de números escritos à mão de 0 a 9, dividida em um conjunto de treinamento e teste. O conjunto pode ser baixado do site da Yann LeCun no formato de arquivo IDX. Se você quiser trabalhar com os dados como imagens no formato PNG, você pode encontrar uma versão convertida aqui.
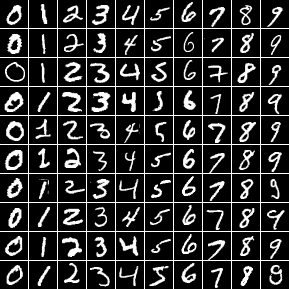
Chars74K
Outra tarefa que pode ser resolvida pelo aprendizado de máquina é a de reconhecimento de caracteres. Para esse efeito, o conjunto de dados Chars74K pode ser utilizado para teste e treino. Ele contém mais de 74.000 imagens de letras e números que são classificadas em 64 classes diferentes. Os caracteres são escritos à mão, obtidos a partir de imagens naturais ou tirados de fontes de computador. Devido à grande quantidade de classes e ao fato de que os dados estão disponíveis como imagens coloridas, esse conjunto de dados é muito mais complexo do que o conjunto MNIST.
 Fonte: http://www.ee.surrey.ac.uk/CVSSP/demos/chars74k/Samples/english.png
Fonte: http://www.ee.surrey.ac.uk/CVSSP/demos/chars74k/Samples/english.png
{kind=link}
Faces
Imagens de faces frontais
O conjunto de dados para imagens de faces frontais foi criado para avaliar os pedidos de reconhecimento de face frontal em imagens. Ele contém imagens de humanos e informações sobre a localização de seus rostos nas imagens dadas pelas coordenadas x e y. Você pode baixar o conjunto aqui.

Labeled Faces in the Wild
Um conjunto comumente utilizado para detecção de face é o Labeled Faces in the Wild. Ele contém mais de 13.000 imagens que foram coletadas da web. Muitas das pessoas no conjunto são representadas por mais de uma imagem, o que é útil para a avaliação de reconhecimento de rosto.

Animais
Oxford-IIIT Pet Dataset
Se você estiver procurando por um extenso conjunto de dados de gatos e cães, você pode verificar o Oxford-IIIT Pet Dataset. Ele cobre 37 categorias de diferentes raças de cães e gatos com 200 imagens por categoria. Ao contrário de muitos outros conjuntos de dados, as imagens incluídas não são do mesmo tamanho. O legal sobre esse conjunto de dados é que não só as imagens são fornecidas, mas também informações sobre a posição do rosto do animal e sobre a frente e o fundo da imagem (veja imagem abaixo).
 Fonte: http://www.robots.ox.ac.uk/~vgg/data/pets/
Fonte: http://www.robots.ox.ac.uk/~vgg/data/pets/
KTH-ANIMALS
No caso de você estar procurando por um conjunto de dados mais geral de animais, vale a pena dar uma olhada no conjunto de dados KTH-ANIMALS. Ele pode ser baixado aqui e fornece imagens para 19 classes diferentes. Cada classe é representada por cerca de 100 imagens de diferentes tamanhos. Tal como no conjunto de dados Oxford-IIIT Pet, há também informações fornecidas sobre a frente e o fundo.
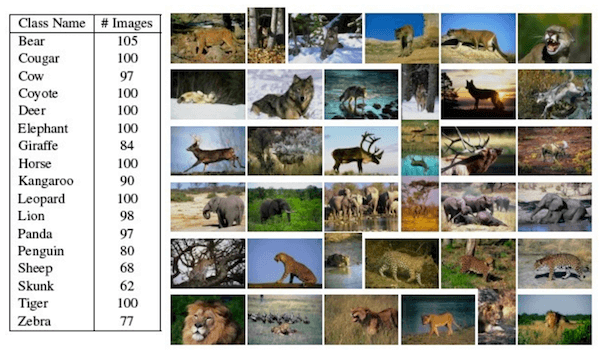 Fonte: http://www.csc.kth.se/~att/Site/Animals.html
Fonte: http://www.csc.kth.se/~att/Site/Animals.html
Vários objetos
CIFAR-10 and CIFAR-100
Para aplicações mais avançadas de classificação de imagem, você pode estar interessado no conjunto de dados CIFAR. Esse conjunto contém imagens coloridas com o tamanho de 32×32 pixels e pode ser baixado no site de Alex Krizhevsky.
O conjunto de dados CIFAR-10 consiste de 60.000 imagens, igualmente distribuídas em 10 categorias. No caso de você estar procurando por um conjunto mais complexo, com mais categorias, você pode usar o conjunto de dados CIFAR-100, que fornece imagens de 100 classes e 20 superclasses.
 Fonte: https://www.cs.toronto.edu/~kriz/cifar.html
Fonte: https://www.cs.toronto.edu/~kriz/cifar.html
Ambos os conjuntos CIFAR podem ser baixados em Python, Matlab ou uma versão binária. Se você preferir trabalhar com os dados como imagens PNG, você pode usar esta ferramenta para converter o conjunto de dados.
STL-10
As imagens fornecidas nos conjuntos de dados CIFAR são muito pequenas, por isso, se você quiser trabalhar com imagens de alta resolução, o conjunto de dados STL-10 pode ser interessante para você. Ele contém imagens rotuladas de 10 classes e é semelhante ao conjunto de dados CIFAR-10, mas as imagens têm o tamanho de 96×96 pixels. Há também menos exemplos rotulados por classe, mas o conjunto tem uma grande coleção de imagens não marcadas que podem ser usadas para o treinamento sem supervisão.
 Fonte: https://cs.stanford.edu/~acoates/stl10/images.png
Fonte: https://cs.stanford.edu/~acoates/stl10/images.png
{kind=link}
***
Christine Wiederer faz parte do time de colunistas internacionais do iMasters. A tradução do artigo é feita pela redação iMasters, com autorização do autor, e você pode acompanhar o artigo em inglês no link: http://blog.webkid.io/datasets-for-machine-learning/#•-Numbers-and-Letters

De 0 a 10, o quanto você recomendaria este artigo para um amigo?