

Este ano, participei da conferência SemTechBiz2013, em San Francisco. Esse é um encontro de criadores e designers da área de tecnologia semântica, pessoas que trabalham em padrões de web semântica, e representantes dos motores de busca, todos se reunindo para discutir o estado da indústria. Havia um foco em busca semântica e marcação de dados estruturados no evento, refletindo a expansão do schema.org e do Google Knowledge Graph, bem como do Bing Snapshots e a crescente influência do Open Graph Protocol.
Aaron Bradley escreveu uma fantástica lista das principais lições da conferência, e se você está tentando se entrosar com a busca semântica, é um excelente ponto de partida.
Os comerciantes têm um rol de atividades à escolha para aumentar a visibilidade, construir uma marca e levar a engajamento. Pode ser difícil de quantificar quando se trabalha com uma coisa nova e quente, especialmente quando as palavras “Google” e “SEO” estão envolvidas. Quando há mudanças fundamentais no cenário de SEO (e eu acredito que estamos perto do início de uma dessas mudanças), a indústria busca profissionais que são frequentemente questionados sobre como organizar uma estratégia em torno das novas opções táticas. Aqui estão cinco perguntas que eu espero esclarecer sobre o estado atual da semântica de SEO e da marcação de dados estruturados:
1. “Semântica de SEO” é um novo termo?
Nós gastamos muito tempo na comunidade de SEO debatendo termos e definições, mesmo quando são atividades estabelecidas que fazemos há anos. Isso é duplamente verdadeiro para pessoas de tecnologia que não são da indústria de pesquisa. Se você tem uma abundância de tempo livre, você pode ir a qualquer Hacker News relacionado a SEO e ver que ainda não há acordo sobre se SEO deve ou não ser um termo ou uma disciplina válida.
Deixando a otimização de lado, na palestra de Aaron na SemTech, acima referenciada, há uma definição concisa de busca semântica, fornecida por Tamas Doszkocs, do WebLib:
Busca semântica é uma pesquisa ou uma pergunta ou uma ação que produz resultados significativos, mesmo quando os itens recuperados não contêm nenhum dos termos da consulta, ou a pesquisa não envolve nenhum texto de consulta.
Isso é um grande ponto de partida para pensar sobre como o Google e o Bing estão se deslocando para os resultados de busca semântica. Justin Briggs escreveu um artigo sobre os resultados da pesquisa de entidade há mais de um ano, e é ainda uma cartilha útil sobre como os motores de busca estão, cada vez mais, caminhando para esses tipos de resultados para consultas dos usuários. No entanto, ainda não há um termo acordado para descrever as atividades sobre alcançar visibilidade nos resultados de busca semântica ou otimizar um motor de busca semântica.
Eu já ouvi de tudo, desde “SEO baseado em entidade” (entity-based) à “SEO de entidade” (entity SEO) e à “Otimização de Busca de Entidade” (Search Entity Optimization), como descritores para otimizar resultados baseados na entidade. Eu, pessoalmente, me inclino para “otimização de busca semântica” ou “semântica de SEO”, mas posso garantir uma coisa: não importa do que você chama isso no final do dia. Ajustar o cenário de busca semântica fará parte da descrição do trabalho do SEO daqui para frente.
2. Como “os resultados de pesquisa baseados na entidade” se parecem agora?
A primeira onda de resultados baseados em entidade no Google foram através de “cartões de resposta” e resultados do Knowledge Graph. Estamos acostumados a ver frequentemente pesquisas no Google para pessoas, lugares, e os resultados de objetos de mídia se parecem com isto:
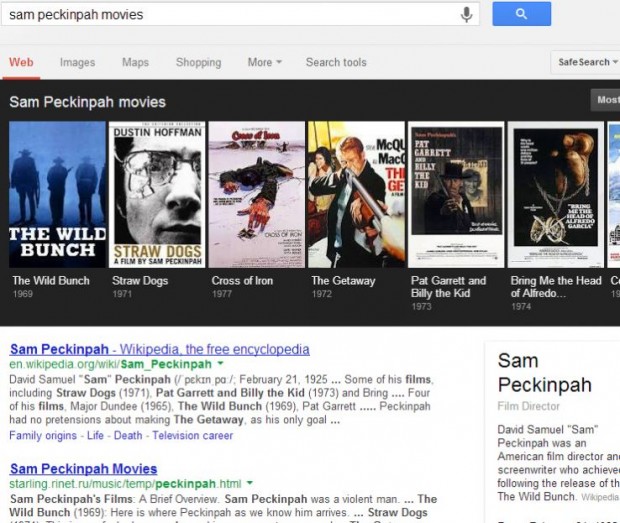
É óbvio que o resultado do Google Knowledge Graph acima é gerado principalmente a partir da entrada Freebase em Sam Peckinpah. A mudança que será muito mais difícil de desconstruir são os resultados de ranking de sites de busca que não otimizam claramente as consultas de palavras-chave específicas, ou podem não conter o que SEOs considerariam fortes perfis de link com correspondência exata ou parcial do texto âncora. Considere este resultado para a frase clássica do filme 2001: A Space Odyssey:
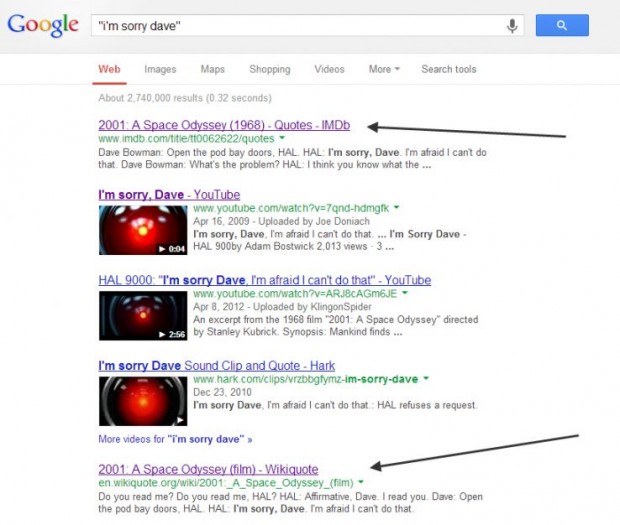
Os clipes do YouTube e outros resultados de busca na primeira página contêm o que você pode esperar ver em termos de otimização on-page e perfis do texto âncora: o uso de palavras-chave no título/META tags/URL, e uma mistura de correspondência exata e parcial de texto âncora nos perfis de link. Mas as páginas do IMDb e do Wikiquote são um pouco diferentes, e não contêm sinais fortes em qualquer dessas áreas. Há alguns links para a página do IMDb, mas relativamente poucos na forma de texto âncora parcial ou de correspondência exata que um SEO pode esperar para ver. Além disso, enquanto a frase é encontrada no conteúdo do corpo da página, os pontos habituais de SEO na URL, texto âncora interna e título de tag HTML não são otimizados para a citação.
Gianluca Fiorelli escreveu recentemente um artigo sobre gráficos e reconhecimento de entidade, que abordou esse tema e como ele pode se relacionar a co-ocorrência e a co-referência em documentos web. O Google lançou o Wikilinks Corpus este ano, e no lançamento eles descrevem um sistema de co-referência para adicionar na resolução da entidade. Especificamente, quando há diferentes menções ou consultas referenciando a mesma entidade através de documentos web?
O projeto Google/UMass Wikilinks fornece um bom exemplo de co-referência em documentos cruzados, com dois documentos web que ambos apontam para a entidade desambígua “Banksy” na Wikipedia:

Ou, no exemplo acima, quando as pessoas estão procurando “I´m sorry, Dave” (“Sinto muito, Dave”), o Google pode facilmente corresponder a consulta à entidade 2001: A Space Odyssey (2001: Uma Odisseia no Espaço) em documentos web que co-referenciam a página do IMDb, e retorna resultados para essa entidade, sem depender de palavra-chave correspondente em tags HTML e texto âncora.
3. Então a palavra-chave morreu?
Curiosamente, eu li dois artigos de SEOs muito afiados que têm uma opinião diferente sobre isso. AJ Kohn traz um argumento convincente de que palavras-chave ainda são importantes, como elas são cruciais para determinar a intenção do usuário e combinar isso com resultados relevantes. Enquanto os resultados do SEO de entidade e do Knowledge Graph tentam adivinhar a intenção do usuário através de localização, personalização e desambiguação da entidade, não há nada mais claro em termos de intenção do que uma série de palavras-chave de “hospitais de Seattle” ou “Qual é o melhor jogo de Xbox 360?”
Mas há um alguns sinais de que a palavra-chave pode estar caindo um pouco como o árbitro final da intenção do usuário. Considere o lançamento “conversional search” do Google, que coloca em camadas o que você procurou, quem você é, e de onde você é como modificadores da intenção de sua consulta. Mesmo SEOs teimosos e velhos estão começando a perceber que existem camadas de intenção implícita nos resultados de pesquisa que não podemos desvendar através de pesquisa de palavras-chave ou links métricas de gráficos.
Mr. Bradley faz um ponto muito marcante em seu documento do SemTechBiz (sério, leia isso): Mobile é a força motriz por trás da revolução de busca semântica. Google, Bing e Yahoo! veem a ascensão da adoção móvel e a morte lenta do PC desktop. Palavras-chave podem nunca morrer, mas elas podem ter um monte de empresas quando se trata de determinar a intenção do usuário e entregar resultados de pesquisa relevantes.
4. Marcação de dados estruturados é um fator de ranking?
Não adoraríamos de saber? Não quero ser rude e responder a minha pergunta com outra pergunta, mas quando foi a última vez que o Google realmente confirmou que algo é um fator em seu algoritmo de ranking? Minha memória diz que foi o anúncio de velocidade do site em 2010. Os leitores devem se sentir livres para me corrigir nos comentários se houver um exemplo mais recente.
Como um modelo mental simplificado, você pode agrupar fatores de motor de pesquisa de classificação em uma destas categorias:
- Sinais de popularidade: Links, bem como a qualidade e a quantidade deles em particular. Outros sinais de visibilidade, como compartilhamento de mídia social se enquadram nessa categoria.
- Sinais de relevância: Muita coisa acontece nesta categoria, mas um bom ponto de referência é a patente do Google na indexação baseada em frase.
- Coisas que afetam drasticamente a experiência do usuário em um site: Sites invadidos no extremo e fatores menores, como a velocidade do site ou o nível de leitura, no outro extremo do espectro.
- Coisas que realmente aparecem nos resultados do mecanismo de busca: Palavras-chave em títulos HTML, URLs e meta descrição de tags (sim, eles afetam o CTR no mínimo).
Estruturação de marcação de dados afeta significativamente os sinais de relevância e a maneira como têm sido tradicionalmente gerados na string da palavra-chave no mundo SEO, bem como a forma como os resultados da pesquisa na verdade aparecem. O cenário das SERP é um longo caminho até os 10 links azuis; vídeo e miniaturas de imagem, miniaturas de autoria e rich snippets de muitos tipos agora alteram fundamentalmente em que os usuários clicam:
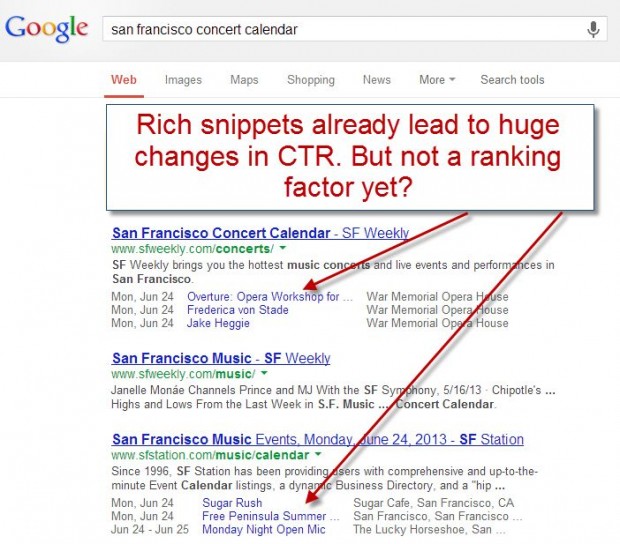
Vai ser interessante ver o que os dados de teste e estudos de correlação nos dizem sobre a marcação de dados estruturados como um fator de rankeamento. Se Google e Bing podem derivar um sinal limpo da presença dessa marcação, ela atende a outros critérios que nós tipicamente usamos para marcar algo como um fator de rankeamento.
5. A implementação da marcação do schema.org realmente prejudicará nossa visibilidade no motor de busca no futuro?
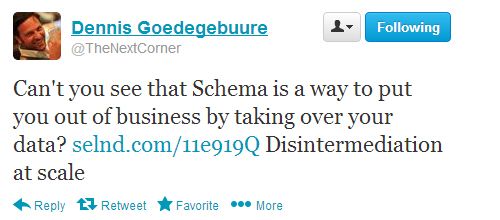
Tem havido um grande número de SEOs que levanta preocupações válidas sobre a implementação de marcação de dados estruturados. Será que ela vai permitir que sites que fazem scraper tirem facilmente os seus dados e os usem para te superar? Ou, pior, o Google vai aspirar os seus dados para seus próprios fins para resultados do Knowledge Graph ou rich snippets cada vez mais sofisticados? Este tweet de Dennis Goedegebuure resume a última preocupação, e pode ser aplicado a Google, Bing, Facebook, Twitter ou qualquer outro mecanismo de busca ou rede de mídia social:
Muitos profissionais da indústria de SEO sentem como se já tivessem visto esse filme antes. Digamos, por exemplo, que você gastou uma quantidade considerável de tempo e dinheiro na otimização de imagens de olho no aumento da sua visibilidade na busca de imagens do Google. A recente mudança de interface do usuário com os resultados de busca de imagens do Google provavelmente teve um impacto negativo e significativo de ROI nesse esforço. Mas há algo muito bom nesse artigo Define Media Group: ainda é uma boa ideia para aderir às melhores práticas de SEO para otimização de busca de imagens, mas as prováveis mudanças como você optar fortemente por priorizar o trabalho contra uma atividade que trará mais tráfego ou visibilidade. O mesmo cálculo de ROI deve ser aplicado à marcação de dados estruturados, seja schema.org, Open Graph Protocol, ou Twitter Cards marcação.
A grande maioria dos elementos de rich snippets e do Knowledge Graph nos resultados da pesquisa são derivadas de Freebase e de um punhado de outras fontes de dados semânticos, como o CIA World Factbook e o MusicBrainz. Se vamos optar ou não por usar mark up em nossos sites terá pouco efeito sobre as SERPs atuais do Google ou do Bing.
No entanto, há uma enorme quantidade de dados ainda presente no bom e velho HTML, e os mecanismos de busca estão interessados em usar dados estruturados para exibir essa informação. Você pode ver limitações de reaquisição e confiança de documentos no link graph em qualquer número de resultados de busca que seja menos que o desejado. Eu acredito que o Google e o Bing irão elevar o nível da qualidade dos resultados de pesquisa por meio de uma maior adoção de marcação de dados semânticos.
Eu também acredito que devemos sempre mantê-los, e todos os outros consumidores de dados estruturados responsáveis por garantir a atribuição adequada e design de interface do usuário responsivo são peças-chave do seu consumo de dados estruturados. O SEO recebeu uma má reputação em alguns círculos como sendo simplesmente um veículo para spam. A realidade é que o trabalho pesado de SEO está por trás de muitos dos melhores resultados de busca que você vai encontrar. Daqui para frente, a mesma diretriz se aplica a dados estruturados.
Um ecossistema web saudável vai encontrar um equilíbrio entre o motor de busca, o usuário e o editor de conteúdo. Vamos continuar a lembrar aos agregadores de nossos dados à medida que continuamos no caminho do SEO semântico.
Pergunta bônus: qual é a melhor jogada para os editores da web?
A taxa de adoção de marcação de dados estruturados terá efeitos profundos sobre como os nossos SERPs se parecerão nos próximos anos. Valerá a pena o esforço para os editores web (pequenos e grandes) para fornecer imediatamente essa marcação?
***
Este artigo é uma republicação feita com permissão. Moz não tem qualquer afiliação com este site. O original está em http://moz.com/blog/semantic-SEO-questions

De 0 a 10, o quanto você recomendaria este artigo para um amigo?